


问题
一个自定义 DSL 的 LSP 服务(Go 实现)需要为编辑器提供语法高亮。高亮依赖一份"词表":哪些标识符是内置元素 哪些是指令 哪些是内置函数。
这份词表在后端 schema 包里已经有了——它同时服务于补全 hover 诊断。问题是前端 Monaco Editor 的 Monarch tokenizer 也需要同样一份列表来做着色。
两边各写一份,迟早不同步。
两条路线
运行时拉取:后端暴露 API,前端 mount 时请求,拿到 JSON 后注册 Monarch 规则。
构建时生成:跑一个 Go 程序读 schema 包的导出切片,输出 .ts 文件到前端目录,前端直接 import。
做了简单的评估之后选了后者。
为什么不走运行时
Monaco 的 Monarch tokenizer 不支持注册后更新词表。调用 monaco.languages.setMonarchTokensProvider 之后,传入的 keywords 数组就固化了——没有 updateTokensProvider API。
这意味着要走运行时,就得:
在
registerBuiLanguage()之前等后端 API 返回如果 API 失败,编辑器要么不着色要么用一份 hardcode 的降级词表
编辑器打开的时序变成异步链:mount → 等 WebSocket → 请求 schema → 注册语言 → 可用
对于一份在发布周期内几乎不变的静态数据,引入这条异步链没有收益。词表跟着构建走,编辑器打开就能用,不存在时序问题。
下面这张图说明两种路线的数据流差异:
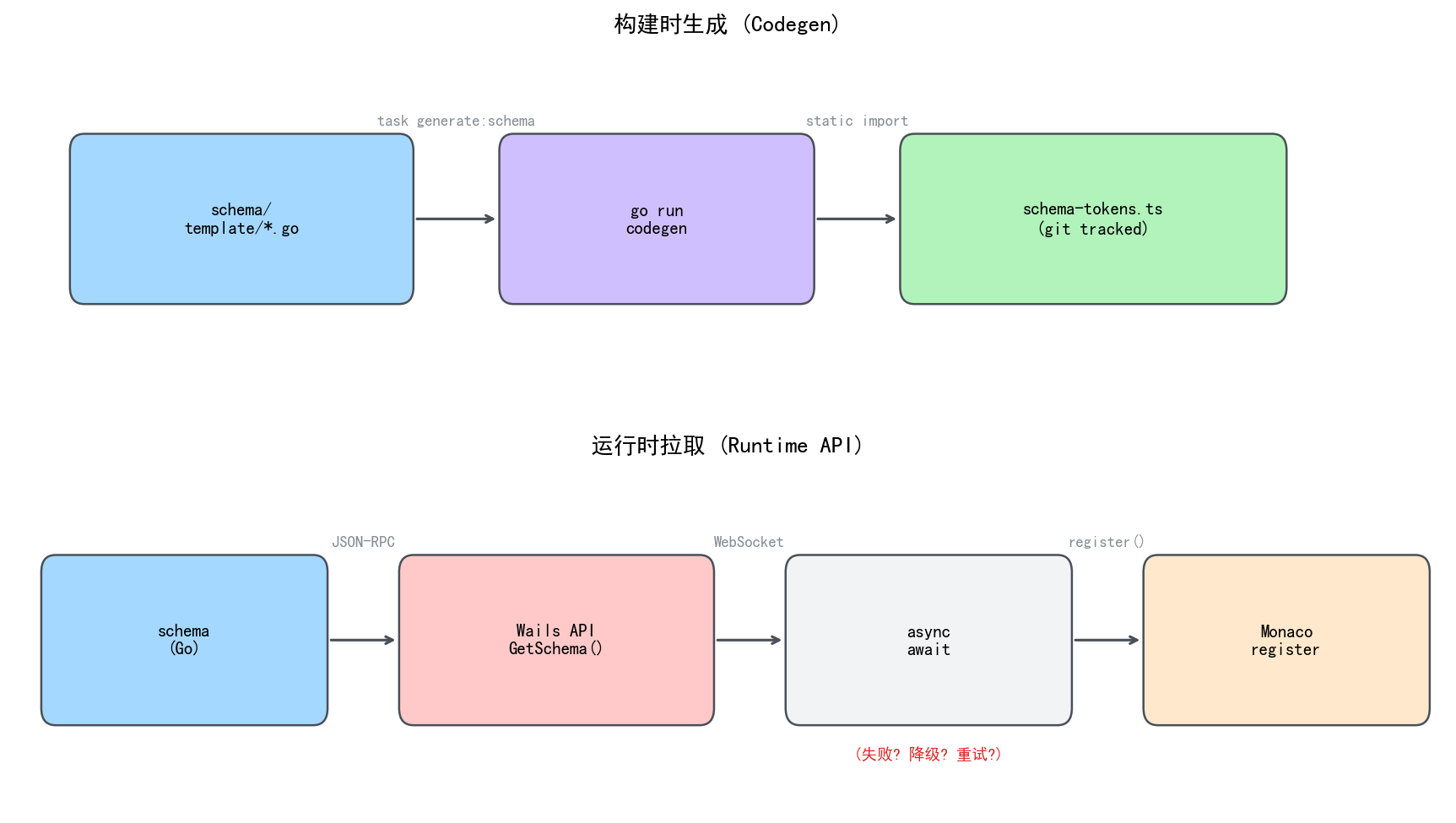
构建时生成怎么做
在 Taskfile(类似 Makefile 的任务编排工具)里加一个 generate:schema 任务,声明源文件和产物:
generate:schema:
sources:
- "internal/lsp/schema/template/*.go"
- "internal/lsp/schema/imports/*.go"
- "internal/lsp/schema/codegen/main.go"
generates:
- "frontend/src/services/lsp/monaco/generated/schema-tokens.ts"
cmds:
- go run ./internal/lsp/schema/codegen
sources 和 generates 让 Task 有增量判断能力——schema 文件没变就跳过。
生成器本身是一个独立的 main 包,导入 schema 包 读它的导出变量 按模板写 TypeScript:
package main
import (
"foundation/internal/lsp/schema/template"
"foundation/internal/lsp/schema/imports"
)
func main() {
// 读 template.Elements 的 Tag 字段 → 输出 builtinElements 数组
// 读 imports.ModuleNames → 输出 moduleNames 数组
// ...
}
产物是一个带 // Code generated ... DO NOT EDIT. 头的 .ts 文件,git tracked。前端 tokenizer 直接 import:
import { builtinElements } from '../generated/schema-tokens';
Go 的 codegen 习惯
Go 生态对 codegen 的接受度非常高——go generate 本身就是语言工具链的一部分。标准库里 stringer、enumer 用了十几年;protobuf gRPC 的 .pb.go 文件也是生成的。
Go 社区形成了几条不成文的共识:
生成的文件 git 提交。不依赖 CI 环境有没有装生成器 不要求每个开发者本地先跑 generate 才能编译。go build 对着已有的 .go / .ts 文件直接过。
生成器是独立的 main 包。放在 cmd/ 或 internal/.../codegen/ 下,不会被主程序编译进去。go run ./path/to/codegen 一行就跑。
产物文件头部标注来源。// Code generated by X. DO NOT EDIT. 是 Go 官方约定,go generate 检测到这行会跳过。
增量由外部工具管理。Go 本身不管 codegen 的 up-to-date 检查;Task / Make / Bazel 这些工具靠 sources / generates 声明来做。
这些习惯的共同指向是:codegen 是一个构建步骤,不是运行时行为。生成完就是普通源文件,不比手写的特殊。
与运行时方案的对比
最后一行是运行时方案唯一的优势——热更新。但对 Monaco tokenizer 不适用(不支持),对我们的场景也不需要(词表随版本发布 不需要不重启就生效)。
前端消费方式
生成的 .ts 文件导出 as const 数组,类型会被 TypeScript 推导为字面量联合。Monarch tokenizer 的 cases 机制支持 @tokenName 引用顶层词表:
export const templateTokenizer = {
tokens: { builtinElements: [...builtinElements] },
tokenizer: {
template: [
[/(<\/?)([A-Z][\w-]*)/, ['delimiter.html', {
cases: { '@builtinElements': 'tag', '@default': 'type' }
}]],
]
}
};
内置元素着色为 tag,工作区用户组件着色为 type。增减一个内置元素只需改后端 schema 重跑 codegen,前端不动一行代码。
什么时候该用运行时
不是所有场景都该走 codegen。当数据满足以下任一条件时,运行时拉取更合适:
数据因用户而异(比如用户自定义的组件列表)
数据高频变化且需要不重启就生效
消费方支持动态更新(比如补全列表——LSP 每次请求都能返回最新结果)
这也是为什么补全和 hover 走 LSP 运行时通信,而高亮走 codegen——前者需要动态感知工作区状态 后者只需要语言规范里的静态词表。
两层各管各的,互不干扰。
参与讨论
(Participate in the discussion)
参与讨论