

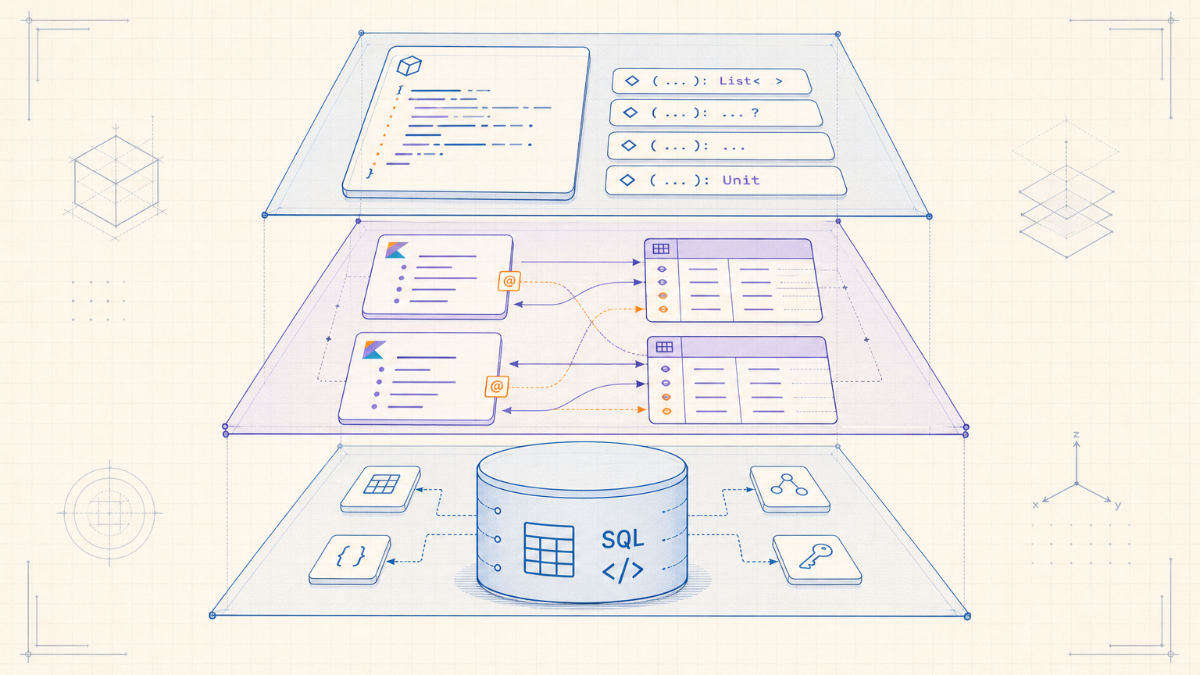
Minecraft 插件开发中,数据持久化是个绕不过去的问题。玩家数据要存、配置要存、状态要存,但插件的运行环境决定了你不可能引入 Hibernate 这种重量级框架——类加载隔离、JAR 体积、运行时依赖冲突,每一个都是坑。
database-ptc-object 是 TabooLib 框架中的对象关系映射模块,设计目标是让开发者用一个 data class 加几个注解就能完成建表、CRUD、事务、关联查询。这篇文章不讲怎么用,而是讲这个模块是怎么一步步设计出来的——从最初的单文件原型,到支持三种数据库方言、子表级联、版本迁移的完整 ORM。
设计动机
TabooLib 原本有一个 database-ptc 模块,提供的是基于键值对的持久化容器。用起来像这样:给一个 key,存一个序列化后的 value。这种模式够用,但不够好——你没有类型安全,没有结构化查询,每次读写都要手动序列化反序列化。
问题的本质是:插件开发者想的是"我有一个 PlayerHome 对象,帮我存起来",而不是"帮我把 username 字段序列化成字符串,拼成一条 INSERT 语句"。
所以 database-ptc-object 的设计目标很明确:
声明式映射——写一个 data class,加注解,建表和 CRUD 自动完成
多数据库透明——同一套代码跑 SQLite、MySQL、PostgreSQL,开发者不需要关心方言差异
轻量无依赖——不引入第三方 ORM 框架,整个模块自包含
渐进式复杂度——简单场景一行代码搞定,复杂场景(事务、关联表、子表)按需开启
第一阶段:最小原型
2024 年 9 月,模块随 TabooLib 6.2.0 正式落地。第一版只有 14 个文件,1157 行代码,但核心骨架已经确立。
注解驱动的元数据
设计从注解开始。一个 ORM 最核心的问题是:怎么知道一个类的哪些字段对应数据库的哪些列?
data class PlayerHome(
@Id val username: UUID,
@Column(type = ColumnTypeSQL.VARCHAR, length = 64)
var world: String,
var x: Double,
var y: Double,
var z: Double
)
@Id 标记逻辑主键,@Column 可选地指定列类型和长度。如果不标 @Column,框架根据 Kotlin 类型自动推断 SQL 类型。
这一步的关键决策是:用构造器参数顺序作为字段发现机制。Kotlin data class 的主构造器参数和字段是一一对应的,通过反射拿到 Constructor.parameters 就能按声明顺序遍历所有字段。这比扫描 Java Field 更可靠——Field 的顺序在不同 JVM 上不保证稳定。
AnalyzedClass:反射元数据的缓存层
反射是昂贵的。每次 CRUD 都重新解析类结构不现实,所以第一版就引入了 AnalyzedClass——一个带缓存的类元数据容器。
class AnalyzedClass private constructor(val clazz: Class<*>) {
val members: List<AnalyzedClassMember> // 字段列表
val primaryMember: AnalyzedClassMember? // @Id 字段
companion object {
private val cache = ConcurrentHashMap<Class<*>, AnalyzedClass>()
fun of(clazz: Class<*>) = cache.getOrPut(clazz) { AnalyzedClass(clazz) }
}
}
ConcurrentHashMap 做单例缓存,同一个类只解析一次。AnalyzedClassMember 封装每个字段的名称、类型、注解信息、是否为主键等元数据。
Container + ContainerOperator:两层抽象
第一版的架构分两层:
Container(容器):管理数据库连接和表的生命周期,负责建表
ContainerOperator(操作器):执行具体的 CRUD,每张表对应一个操作器
Container 是抽象类,ContainerSQL 和 ContainerSQLite 分别处理 MySQL 和 SQLite 的建表逻辑。ContainerOperator 接收一个 Table 对象和 DataSource,封装所有 SQL 操作。
用户入口是 PersistentContainer DSL:
val container = persistentContainer(db()) {
new<PlayerHome>()
}
一行代码:解析类 → 建表 → 注册操作器。
CustomType:类型扩展点
Kotlin 的类型不可能和 SQL 类型一一对应。UUID、枚举、自定义对象都需要序列化。第一版就设计了 CustomType 接口:
interface CustomType {
val type: Class<*>
fun serialize(value: Any): Any
fun deserialize(value: Any): Any
}
通过 CustomTypeFactory 注册自定义类型转换器。框架内置了 UUID、Location 等常见类型的转换,开发者也可以注册自己的。
这一步的设计原则是开放封闭——框架不需要预知所有可能的类型,只需要提供扩展点。
第二阶段:DataMapper 与快捷操作
最小原型能跑,但用起来还是偏底层。开发者需要手动从 Container 拿 operator,再调 find、insert。这不够 Kotlin。
这一步引入了 DataMapper 接口和 Kotlin 委托语法,让使用体验变成:
val homeTable by mapper<PlayerHome>(dbFile("data.db"))
// 查
homeTable.findById(playerId)
homeTable.findAll { "world" eq "world_nether" }
// 写
homeTable.insert(newHome)
homeTable.update(modifiedHome)
DataMapper:类型安全的 CRUD 门面
DataMapper<T> 是一个纯接口,定义了完整的操作集合:
插入:
insert/insertBatch/insertAndGetKey查询:
findById/findOne/findAll/count更新:
update/updateByKey/upsert删除:
delete/deleteWhere事务:
transaction { ... }原生:
rawSelect/rawUpdate/rawDelete
接口设计的关键是不暴露 SQL 细节。findById 接收一个 Any 类型的 ID 值,内部自动根据 @Id 注解定位;findAll 接收一个 Filter lambda,用 DSL 构建 WHERE 条件。
MapperDelegate:by 关键字的魔法
Kotlin 的属性委托让初始化代码彻底消失:
inline fun <reified T> mapper(
source: Any,
noinline config: MapperConfig<T>.() -> Unit = {}
): ReadOnlyProperty<Any?, DataMapper<T>>
by mapper<T>(...) 做了三件事:
根据 source 类型创建 Container(File → SQLite,ConfigurationSection → MySQL/PostgreSQL)
解析类 T 的元数据并建表
返回一个
DataMapperImpl实例
这是典型的延迟初始化——第一次访问属性时才触发建表,避免服务器启动时的阻塞。
Cursor 与 Page:大数据集处理
当表里有几万条记录时,findAll 把所有数据一次性加载到内存显然不行。这一步引入了两个工具:
Page:分页查询,
findAll(page = Page(1, 20))返回第一页的 20 条Cursor:流式游标,逐条处理不占内存,适合批量导出场景
homeTable.selectCursor { "active" eq true }.forEach { home ->
// 逐条处理,内存中同时只有一条记录
}
QueryCache:读缓存层
插件场景的读写比通常很高——玩家数据读取频繁,写入相对稀少。QueryCache(后来演进为 L2Cache)提供了两层缓存:
BeanCache:按 ID 缓存单个对象
QueryCache:按查询条件缓存结果列表
写入操作自动失效对应缓存,保证一致性。开发者通过配置开启:
val homeTable by mapper<PlayerHome>(dbFile("data.db")) {
cache {
beanCache { maximumSize = 10000; expireAfterAccess = 600 }
queryCache { maximumSize = 1000; expireAfterAccess = 600 }
}
}
第三阶段:事务支持
到这里模块已经能用了,但还缺一个生产级数据层必备的能力——事务。
事务的核心问题是:多个操作必须共享同一个数据库连接。原本的 ContainerOperator 每次操作都从 DataSource 拿新连接,事务下不行。
Connection 共享机制
ContainerOperatorImpl 增加了一个 sharedConnection 字段:
class ContainerOperatorImpl(
override val table: Table<*, *>,
override val dataSource: DataSource,
private val sharedConnection: Connection? = null,
// ...
) {
val isTransactional: Boolean
get() = sharedConnection != null
fun withConnection(connection: Connection): ContainerOperatorImpl {
return ContainerOperatorImpl(table, dataSource, connection, ...)
}
}
非事务模式下 sharedConnection 为 null,每次操作走 DataSource。事务模式下传入一个共享连接,所有操作都用这一个。withConnection 是个工厂方法,根据现有 operator 复制出一个事务版本。
TransactionContext:DSL 入口
事务上下文封装了用户视角的事务操作:
container.transaction {
val homes = get<PlayerHome>()
val stats = get<PlayerStats>()
homes.insert(listOf(newHome))
stats.update(playerStats)
if (someError) {
rollback() // 标记回滚
}
}
get<T>() 返回的是事务感知的 operator——共享连接、共享事务边界。block 执行完毕后,根据 rollbackOnly 标志决定 commit 还是 rollback;中途抛异常自动回滚。
事务传播:嵌套事务的连接复用
后来增加了一个细节:嵌套 transaction { } 应该复用外层连接,而不是开一个新事务。这通过 ThreadLocal 实现:
companion object {
internal val currentConnection = ThreadLocal<Connection>()
}
进入事务时把 Connection 设到 ThreadLocal,新的 transaction { } 调用先查 ThreadLocal——有就直接复用,没有才开新连接。这一步对应业内常说的"传播行为 REQUIRED",但实现上只用了一个 ThreadLocal,没引入复杂的传播策略枚举。够用就行,不要过度设计。
第四阶段:PostgreSQL 支持
一开始模块只支持 MySQL 和 SQLite。要支持 PostgreSQL 时,第一反应是再加一个 ContainerPostgreSQL,照抄 ContainerSQL 的代码改改就行。
但这条路走了不久就发现问题——ContainerSQL 和 ContainerSQLite 已经有大量重复代码,每加一种数据库重复就翻倍。建表逻辑、列类型映射、索引创建,三份几乎一样的代码用不同的 SQL 方言重写。
这是个明显的坏味道,但当时为了快速支持 PostgreSQL,先把功能加上了。新增的 ContainerPostgreSQL 处理了几个关键差异:
列名引用:MySQL 用反引号,PostgreSQL 用双引号
自增主键:MySQL 用
AUTO_INCREMENT,PostgreSQL 用SERIAL字符串类型:MySQL 的
VARCHAR(64)在 PostgreSQL 中需要不同的列类型映射
这次提交还顺带升级了 MySQL 驱动版本。但代码重复的问题留到了后面的重构。
Schema 与版本迁移
PostgreSQL 有 Schema 概念,一个数据库可以分多个命名空间。@TableName 注解扩展了 schema 参数:
@TableName("player_home", schema = "minecraft")
data class PlayerHome(...)
建表时自动 CREATE SCHEMA IF NOT EXISTS minecraft,表名解析为 minecraft.player_home。这里踩过一个坑——PostgreSQL 索引名不能含点号,所以索引名要把 schema 前缀剥掉。
同时引入了手动建表和版本迁移两个机制:
val homeTable by mapper<PlayerHome>(dbFile("data.db")) {
// 跳过自动建表,用户提供完整 SQL
manualTable("CREATE TABLE IF NOT EXISTS player_home (...)")
// 或者:版本迁移
migration {
version(1, "ALTER TABLE player_home ADD COLUMN x DOUBLE DEFAULT 0")
version(2, "ALTER TABLE player_home ADD COLUMN z DOUBLE DEFAULT 0")
}
}
迁移机制通过一个 _ptc_meta 元数据表跟踪当前版本号。每次启动框架检查版本,按升序执行未应用的迁移 SQL。这是从 Flyway / Liquibase 借来的思路,但只保留了核心机制,没有 checksum、没有回滚脚本——够用就好。
第五阶段:容器类型子表与关联表
到这里,简单类型字段的映射已经没问题了。但现实中的数据结构不可能全是扁平的——玩家有多个家、有物品列表、有属性键值对。List<String>、Map<String, Int> 这些集合类型怎么存?
有两条路:
序列化成 JSON 塞进一个 TEXT 列(简单但不能查询)
拆成子表,外键关联(规范但复杂)
database-ptc-object 两条路都支持,由用户选择。
集合 CustomType:单列存储
对于简单场景(不需要对集合元素做独立查询),把整个集合序列化成 JSON 存进一列是最省事的。通过 CustomType 的 elementType 字段标识"这是一个集合类型转换器":
interface CustomType {
val type: Class<*>
val elementType: Class<*>? // 非 null 时表示集合 CustomType
get() = null
fun serialize(value: Any): Any
fun deserialize(value: Any): Any
}
框架在写入时检查字段类型,如果匹配到集合 CustomType,就用它的 serialize 把整个 List<XXXData> 转成字符串存入一列。读取时反序列化回来。
Collection Accessor:子表存储
当你需要对集合元素做独立 CRUD(比如"删除玩家的第三个家"而不是"读取全部家再过滤"),就需要真正的子表。
框架自动为带 @Collection 语义的字段创建子表。子表名规则是 {父表名}__{字段名},包含一个外键列关联父记录的 @Id。
player_home (主表)
├── id: INT (PK)
├── username: VARCHAR
└── world: VARCHAR
player_home__tags (子表)
├── id: INT (PK)
├── __fk__: INT (外键,指向 player_home.id)
├── __key__: VARCHAR (Map 的 key)
└── __value__: VARCHAR (Map 的 value)
这里的设计难点是连接池死锁。第一版的实现在查询主表时,拿着 ResultSet 不释放,就去查子表——一个连接等另一个连接,如果连接池满了就死锁。
解决方案是两阶段读取:先把主表 ResultSet 的数据全部读到内存中(Map 形式),关闭 ResultSet 释放连接,再去查子表。牺牲一点内存换来死锁消除。
CollectionAccessor 提供了 DatabaseMap / DatabaseList / DatabaseSet 三个代理类,实现标准 MutableCollection 接口。对代理的修改直接转化为 SQL 操作:
val props: MutableMap<String, String?> = mapper.mapOf(playerId, "props")
props["key1"] = "value1" // INSERT INTO player__props ...
props.remove("key1") // DELETE FROM player__props WHERE __key__ = 'key1'
@LinkTable:关联表级联
子表解决的是"一个字段存多值"。还有一种场景:一个类引用另一个类,两个类各有自己的表。
data class PlayerHome(
@Id val id: Int,
var world: String,
@LinkTable val owner: PlayerProfile // 关联到另一张表
)
@LinkTable 标记的字段不会在主表中展开为多列,而是存储一个外键值(关联类的 @Id)。查询时自动 JOIN,写入时级联保存。
LinkTableHandler 负责级联逻辑:
写入:深度优先递归,先保存最深层的关联对象,确保外键引用完整
查询:构建 JOIN SQL,用列名前缀区分主表和关联表的字段
环检测:通过
visited集合避免 A→B→A 的无限递归
fun cascadeSaveLinkedObjects(
typeClass: AnalyzedClass,
dataList: List<Any>,
visited: MutableSet<Class<*>> = mutableSetOf()
) {
if (!typeClass.hasLinkMembers) return
visited.add(typeClass.clazz)
for (member in typeClass.linkMembers) {
val linkClass = member.linkTableClass ?: continue
if (linkClass in visited) continue // 环检测
// 深度优先:先保存更深层的关联对象
cascadeSaveLinkedObjects(linkedTypeClass, linkedObjects, visited)
// 再保存当前层
operator.upsert(linkedObjects)
}
}
这里有一个设计取舍:级联保存用的是 upsert(存在则更新,不存在则插入),而不是无条件 insert。因为关联对象可能已经被别的主对象保存过了——比如多个玩家的家都关联同一个 PlayerProfile。
第六阶段:架构重构
重构后的架构如下图所示,每一层职责清晰、依赖方向单一。
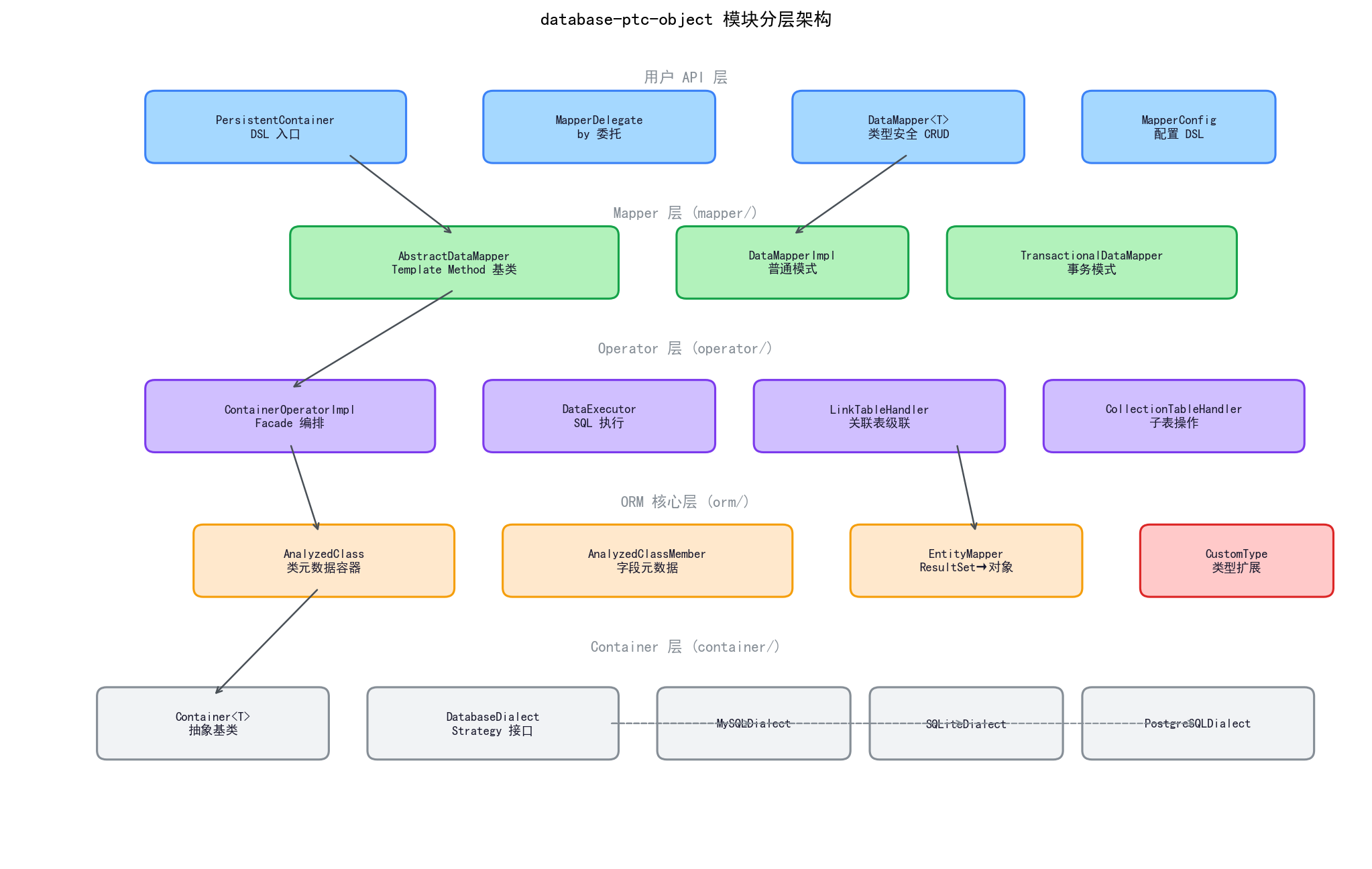
到 2026 年 2 月,模块已经膨胀到几千行代码。几个文件变得庞大:
ContainerOperatorImpl.kt超过 900 行,里面混着主表 CRUD、子表操作、LinkTable 级联AnalyzedClass.kt超过 400 行,既是元数据容器又负责 ResultSet 读取和实例创建ContainerSQL/ContainerSQLite/ContainerPostgreSQL三个类大量重复的建表逻辑
这次重构的指导思想是四个设计模式的组合应用:
Strategy:DatabaseDialect 消除方言重复
提取 DatabaseDialect 接口,每种数据库实现为一个单例:
interface DatabaseDialect {
fun createTable(type: AnalyzedClass, name: String, host: Host<*>): Table<*, *>
fun createCollectionTable(...): Table<*, *>
fun postInit(container: Container<*>) {}
}
object MySQLDialect : DatabaseDialect { ... }
object SQLiteDialect : DatabaseDialect { ... }
object PostgreSQLDialect : DatabaseDialect { ... }
原来三个 Container 子类各自 200+ 行的建表逻辑,全部归入 DatabaseDialect.kt 一个文件。Container 子类变得极薄——只需要声明用哪个方言:
class ContainerSQL(...) : Container<SQL>(host) {
override val dialect = MySQLDialect
}
class ContainerSQLite(...) : Container<SQLite>(host) {
override val dialect = SQLiteDialect
}
这一步的收益是新增数据库方言只需要加一个 Dialect 实现,不用动 Container 层。
Template Method:AbstractDataMapper 提取公共基类
DataMapperImpl 和 TransactionalDataMapper 有大量相同的 CRUD 代码。唯一的差异是:
operator 来源不同(动态查找 vs 构造注入)
读操作是否走缓存
事务和生命周期行为
提取 AbstractDataMapper 基类,用抽象方法定义差异点:
abstract class AbstractDataMapper<T> : DataMapper<T> {
protected abstract val type: Class<T>
protected abstract val operator: ContainerOperator
protected abstract val cache: L2Cache?
// 子类可覆写为走缓存
protected open fun <R> executeRead(key: String, vararg args: Any?, query: () -> R): R = query()
// 公共 CRUD 实现
override fun insert(data: T) {
operator.insert(listOf(data as Any))
invalidateOnInsert()
}
// ...
}
DataMapperImpl 只需要覆写 executeRead 加上缓存逻辑,TransactionalDataMapper 只需要覆写 operator 的获取方式。公共代码归一处,差异代码各归各位。
SRP:EntityMapper 从 AnalyzedClass 中分离
AnalyzedClass 原本身兼两职:类结构元数据 + ResultSet 读取/实例创建。这违反单一职责。
拆出 EntityMapper——专门负责 ResultSet → 对象的映射:
class EntityMapper<T> private constructor(private val analyzedClass: AnalyzedClass) {
fun read(result: ResultSet): Map<String, Any?>
fun readWithLinks(result: ResultSet, prefix: String = ""): Map<String, Any?>
fun createInstance(map: Map<String, Any?>): T
}
AnalyzedClass 变回纯元数据容器(字段列表、注解信息、类型推断),不再包含任何 I/O 逻辑。
Facade + Composite:拆分 ContainerOperatorImpl
900 行的 ContainerOperatorImpl 拆成三个 Handler:
DataExecutor:接口,定义 SQL 执行能力(获取连接、设置 quoter)
LinkTableHandler:封装 @LinkTable 级联保存和 JOIN 查询
CollectionTableHandler:封装容器子表的 CRUD
ContainerOperatorImpl 变成 Facade——把请求分发给对应的 Handler,自身只保留编排逻辑。
分包结构
重构后的包结构:
taboolib/expansion/
├── container/ # 容器层:Container + Dialect
│ ├── Container.kt
│ ├── ContainerSQL.kt
│ ├── ContainerSQLite.kt
│ ├── ContainerPostgreSQL.kt
│ └── DatabaseDialect.kt
├── orm/ # ORM 核心:元数据 + 映射
│ ├── AnalyzedClass.kt
│ ├── AnalyzedClassMember.kt
│ └── EntityMapper.kt
├── mapper/ # DataMapper 层:用户 API
│ ├── AbstractDataMapper.kt
│ ├── DataMapperImpl.kt
│ └── TransactionalDataMapper.kt
├── operator/ # 操作器层:SQL 执行
│ ├── ContainerOperatorImpl.kt
│ ├── DataExecutor.kt
│ ├── LinkTableHandler.kt
│ └── CollectionTableHandler.kt
├── Annotations.kt # 注解定义
├── CustomType.kt # 类型扩展
├── DataMapper.kt # DataMapper 接口
├── ContainerOperator.kt # ContainerOperator 抽象类
├── PersistentContainer.kt # DSL 入口
├── MapperDelegate.kt # by 委托
└── ...
公开 API 保持不变——用户代码不需要任何修改。内部实现从扁平结构变成按职责分层的子包,每个文件 100-300 行,职责清晰。
设计复盘
回看整个开发过程,几条线索贯穿始终。
渐进式设计的节奏
模块不是一次设计出来的。从第一版 14 个文件到现在 30+ 个文件,每一步都是"遇到问题 → 解决问题 → 发现新问题"的循环。
第一版解决了"data class → 表"的映射
快捷操作解决了"底层 API 太啰嗦"的体验问题
事务解决了"多操作原子性"的正确性问题
子表和 LinkTable 解决了"复杂数据结构"的表达能力
重构解决了"代码膨胀后的可维护性"问题
每一步都不是预先规划好的,而是需求驱动的自然演进。如果一开始就设计子表系统和版本迁移,模块可能到现在还没上线。
三个关键的设计决策
决策一:构造器参数作为字段发现机制。 这规避了 Java Field 顺序不稳定的问题,但也带来了约束——data class 必须有主构造器。后来通过 fieldScanMode(无参构造器 + 字段扫描)做了兜底,让普通 Java 类也能用。
决策二:ContainerOperator 和 DataMapper 分两层。 ContainerOperator 是底层的、表级别的操作器,不关心类型安全。DataMapper 是上层的、带泛型的用户 API。这样 IoC 容器(database-ioc 模块)可以直接操作 ContainerOperator,不用知道具体的实体类型。
决策三:先加功能后重构。 PostgreSQL 支持加进来时明知有重复代码,但还是先发布再说。等功能稳定、用户反馈收集够了,再统一重构。这不是技术债的借口,而是刻意的节奏把控——未验证的抽象比重复代码更危险。
踩过的坑
连接池死锁:查主表时持有 ResultSet 又去查子表,解法是两阶段读取
PostgreSQL 列名引用:反引号在 PostgreSQL 中是非法字符,用
asFormattedColumnName()统一处理SQLite 的 @Id 语义:SQLite 中 PRIMARY KEY 强制唯一,但 MySQL 中 KEY 只是索引不强制唯一,同一套注解在两种数据库下行为不同,需要在文档中明确说明
Kotlin 注解目标:
@Id var x注解可能落在 property 而不是 field 上,需要通过$annotations合成方法兜底检查
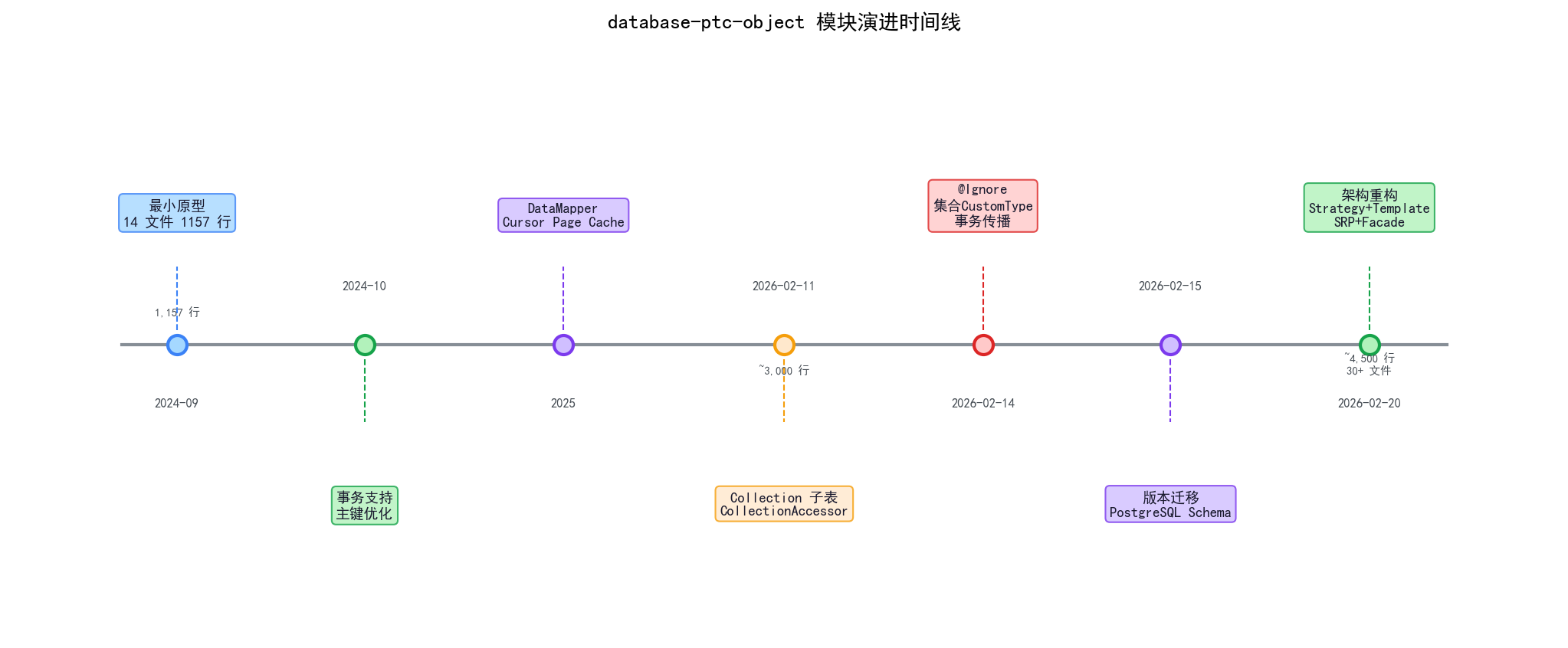
总线图
2024-09 ─── 最小原型(14 文件,1157 行)
AnalyzedClass + Container + ContainerOperator
│
2024-10 ─── 事务支持 / 主键优化
│
2025-?? ─── DataMapper + Cursor + Page + QueryCache
│
2026-02-11 ─ Collection 子表 + CollectionAccessor
│
2026-02-14 ─ @Ignore 注解 + 集合 CustomType + 事务传播
│
2026-02-15 ─ 手动建表 + 版本迁移 + PostgreSQL Schema
│
2026-02-20 ─ 架构重构:Strategy + Template Method + SRP + Facade
│
2026-03 ─── SQLite @Id 行为修正
从一个 1000 行的原型到一个生产级 ORM,核心方法论就一条:让每一步的设计决策都有对应的真实痛点驱动。不要为假设中的需求写代码,不要为未来可能的扩展做架构——等问题真正出现时再解决它,你会发现解决方案比预想中简单得多。
参与讨论
(Participate in the discussion)
参与讨论