

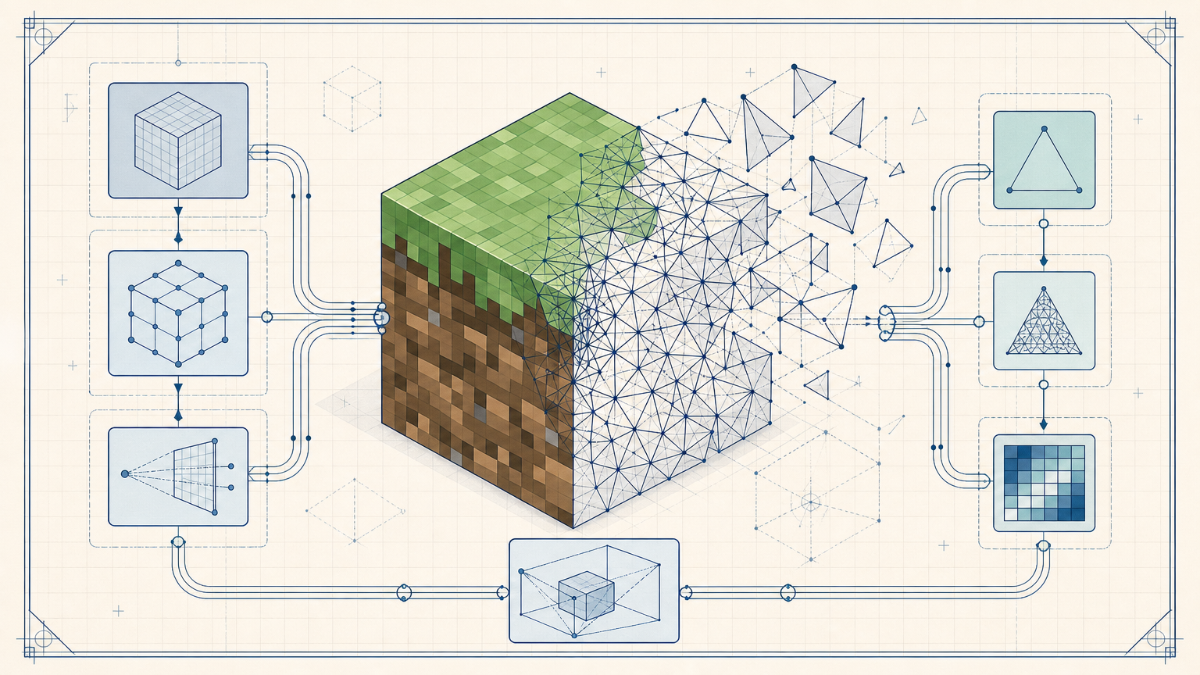
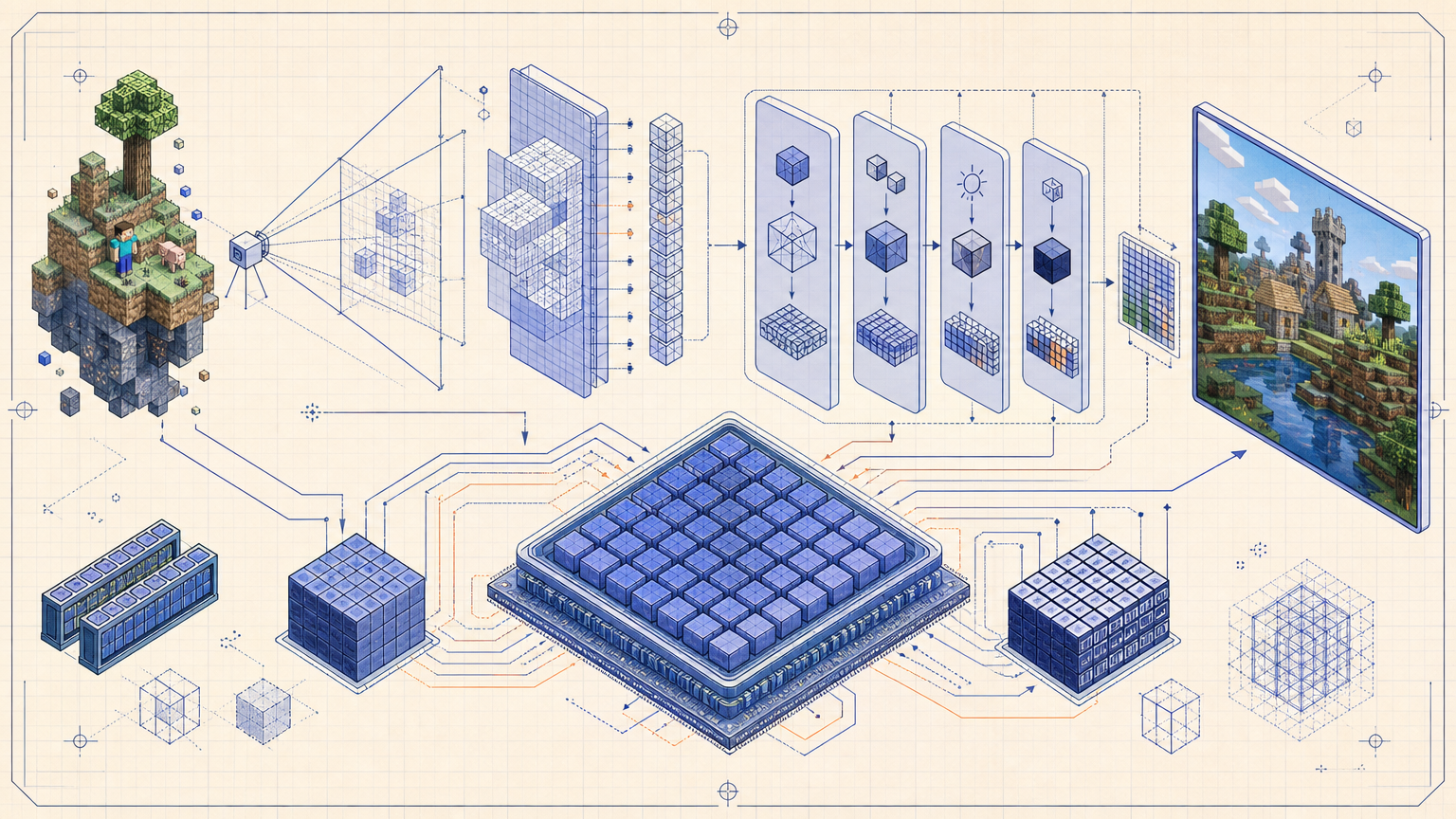
我把朋友的笔记结合最新的 MC 客户端源码重新整理了一遍,补充了必要的前置知识,尽量让没上过图形学课的同学也能跟上。
1.1 GPU 与图形渲染基础
这一切的一切都得从一个问题说起:屏幕上的画面是怎么来的?
渲染是什么
做后端的同学对"请求 -> 处理 -> 响应"这个模型很熟悉。渲染其实也是一样的流程,不过输入是坐标数据,输出是一张图片:
输入:方块坐标 玩家位置 模型数据 纹理贴图
处理:坐标变换 光栅化 着色 混合
输出:一帧画面(一张 1920×1080 的像素矩阵)
游戏每秒要输出 60 帧画面,每帧要处理几十万个三角形。这个吞吐量靠 CPU 单线程是扛不住的。
CPU 和 GPU 的本质区别
如果拿后端做类比:CPU 像一台配置拉满的单体服务器,什么复杂逻辑都能跑但并发有限;GPU 像一个由几千台微型 worker 组成的集群,每个 worker 只能做简单运算但可以同时处理成千上万个请求。
屏幕 1920×1080 有两百万个像素,每个像素都要独立算颜色,算法几乎一样。这不就是天然的 map 操作吗?所以 GPU 干渲染天经地义。
显存(VRAM)
GPU 有自己的专用内存叫显存。
为什么不直接用系统内存?CPU 和 GPU 之间通过 PCIe 总线通信,带宽有限延迟也高。如果每一帧都要从系统内存搬数据过去,这条总线就成了瓶颈——就像微服务之间网络 IO 太频繁反而比单体还慢。
所以策略是:初始化时一次性把纹理 模型数据 着色器程序上传到显存,之后 GPU 渲染时直接本地读取。

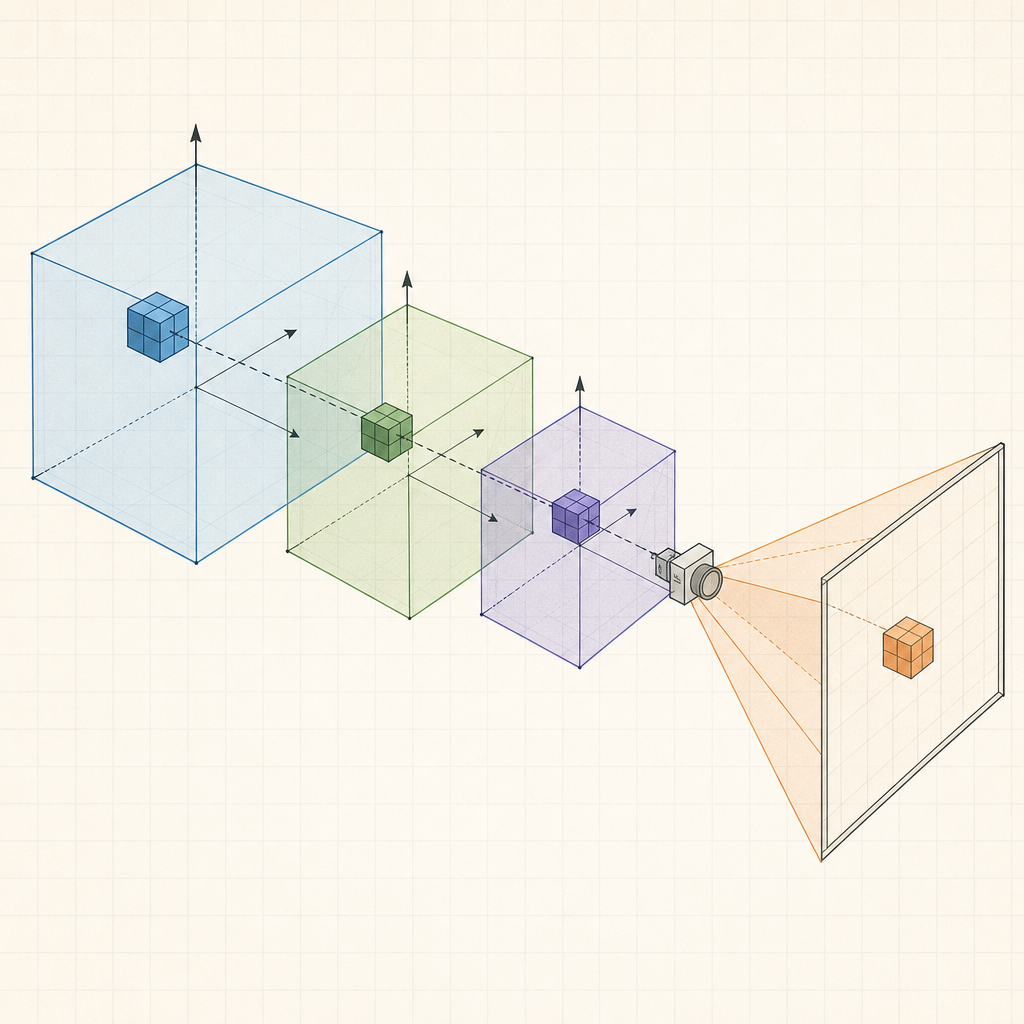
这张图回答一个问题:CPU/内存 和 GPU/显存 之间的数据怎么流动。
GPU 的并行架构
展开讲一下 GPU 内部是怎么组织的。
GPU 内部由大量流式多处理器(SM / CU) 组成,每个 SM 里有若干核心(CUDA Core / Stream Processor)。这些核心被分成固定大小的组叫 Warp(NVIDIA 32 个一组)或 Wavefront(AMD 64 个一组)。同一个 Warp 内的核心在同一时刻执行同一条指令,只是各自处理不同的数据——这就是 SIMT(Single Instruction Multiple Threads) 模型。
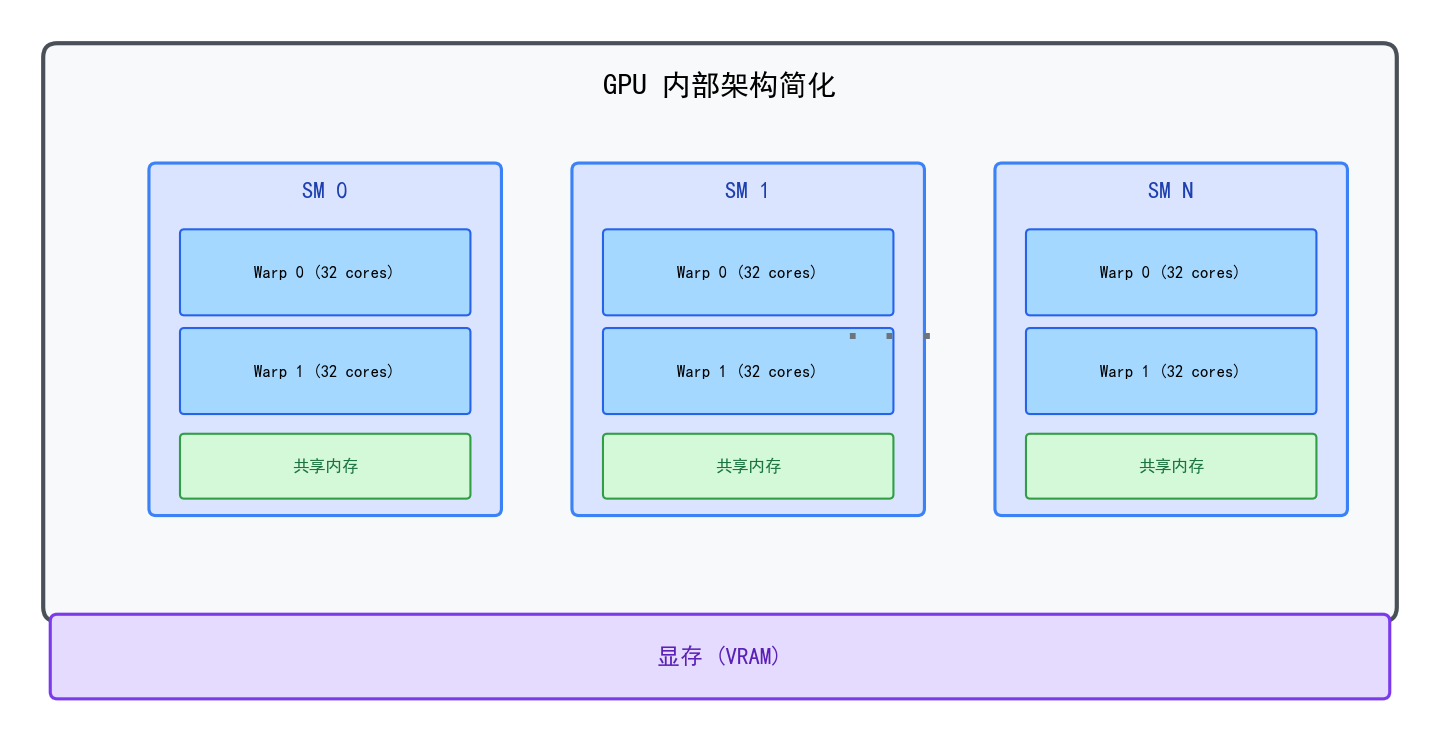
这张图展示了 GPU 内部的层级结构——多个 SM 各自包含多个 Warp,每个 Warp 内 32 个核心锁步执行同一条指令。
对渲染来说意味着什么?顶点着色器对每个顶点执行一次——如果有 10000 个顶点,GPU 会把它们分成若干批次分配到各个 Warp 上并行处理。片段着色器同理,2 百万个像素被拆成 Warp 粒度的任务并发执行。
因此着色器代码里尽量避免分支(if/else),因为同一个 Warp 内如果有的线程走 if 有的走 else,两个分支都要执行——这叫 Warp Divergence,会浪费一半算力。
数据传输:PCIe 总线
CPU 和 GPU 之间通过 PCIe 总线通信。PCIe 4.0 x16 的理论带宽约 32 GB/s,听起来很大但相比显存带宽(几百 GB/s)差了一个数量级。
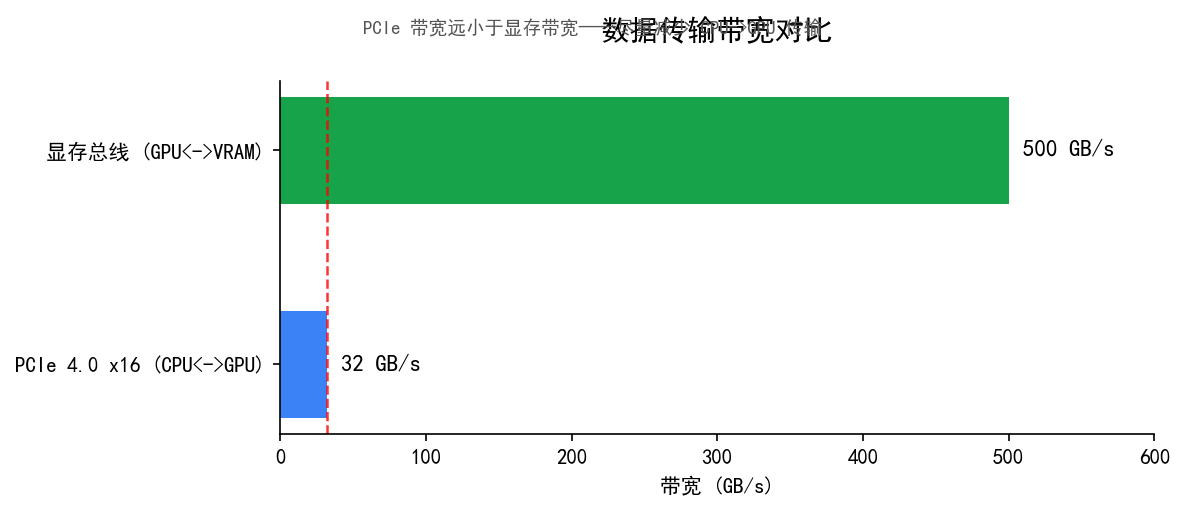
这张图直观展示了 PCIe 和显存带宽之间的巨大差距——这就是"减少 CPU→GPU 传输"成为优化核心原则的原因。
这就是为什么"减少 CPU 到 GPU 的数据传输"是图形优化的核心原则。VBO 的意义正在于此——数据提前存好,不用每帧搬运。
OpenGL 的角色
不同显卡厂商(NVIDIA AMD Intel)的硬件实现完全不一样。OpenGL 是一套标准化的抽象接口——类似 JDBC 之于不同数据库驱动:
你的代码 -> OpenGL API -> 显卡驱动(不同厂商各自实现) -> GPU 硬件
你只管调 glDrawArrays(),具体怎么翻译成硬件指令是驱动的事。
Minecraft Java 版通过 LWJGL(Lightweight Java Game Library)调用 OpenGL。类似的图形 API 还有 Vulkan(更底层 跨平台)、DirectX(Windows 专属)、Metal(Apple 专属)。
三角形:渲染的原子操作
GPU 渲染的最小单位不是像素,是三角形。所有几何体最终都要拆成三角形再喂给 GPU。
为什么是三角形而不是四边形?三个原因:
三个点一定共面(四个点可能不共面,四边形可能是扭曲的)
三角形一定是凸多边形(不会有凹陷导致填充歧义)
任何复杂形状都能三角剖分
Minecraft 里一个方块 = 6 个面 × 每面 2 个三角形 = 12 个三角形。一个满载区块(16×16×256)理论极限是 786,432 个三角形,实际 MC 会剔除看不见的面,远低于这个数字。
帧和帧率
一帧 = 一张静态画面。游戏本质上就是高速翻页动画。
60 FPS 意味着每帧只有 16.67ms 的预算。这 16ms 内要完成:
CPU 阶段:游戏逻辑更新(tick) 确定可见物体 组装顶点数据
GPU 阶段:顶点变换 光栅化 着色 测试混合
显示:帧缓冲内容送到显示器
CPU 和 GPU 是流水线式并行的——CPU 准备第 N+1 帧的数据时,GPU 在渲染第 N 帧。任何一方超时都会导致掉帧。
1.2 渲染管线
上一节讲了 GPU 负责把数据变成画面。但具体怎么变?这就是**渲染管线(Rendering Pipeline)**要回答的问题。
用后端思维理解管线
做后端的同学对"中间件链"很熟悉——请求经过认证 限流 路由 业务逻辑 序列化等中间件后变成响应。渲染管线也是这个模式:顶点数据经过一系列固定阶段后变成像素。
区别在于:部分阶段是固定的(GPU 硬件写死),部分阶段是可编程的(你可以写代码注入自己的逻辑)。可编程的部分就是着色器(Shader)。

这张图回答一个问题:顶点数据从进入 GPU 到变成屏幕像素,中间经过哪些阶段。
阶段 1:顶点输入
管线的入口。你把顶点数据喂给 GPU,每个顶点是一个数据包:
顶点0: 位置(-0.5, -0.5, 0.0), 颜色(1,0,0,1), 纹理坐标(0.0, 0.0)
顶点1: 位置( 0.5, -0.5, 0.0), 颜色(0,1,0,1), 纹理坐标(1.0, 0.0)
顶点2: 位置( 0.0, 0.5, 0.0), 颜色(0,0,1,1), 纹理坐标(0.5, 1.0)
三个顶点定义一个三角形。后续所有阶段都围绕这些数据展开。
阶段 2:顶点着色器(可编程)
这一步的关键是——你可以写代码控制它。
顶点着色器对每个顶点执行一次,核心任务是坐标变换:把顶点从模型自身的坐标系(模型空间)变换到屏幕能理解的坐标系(裁剪空间)。
#version 150
in vec3 Position; // 顶点位置
in vec4 Color; // 顶点颜色
in vec2 UV0; // 纹理坐标
uniform mat4 ModelViewMat; // 模型视图矩阵(由 CPU 每帧传入)
uniform mat4 ProjMat; // 投影矩阵(由 CPU 每帧传入)
out vec4 vertexColor; // 传给下一阶段
out vec2 texCoord; // 传给下一阶段
void main() {
// 核心:坐标变换,把模型空间的点变换到裁剪空间
gl_Position = ProjMat * ModelViewMat * vec4(Position, 1.0);
// 直接透传
vertexColor = Color;
texCoord = UV0;
}
这就是 MC 里 .vsh 文件的内容。uniform 类似于全局配置——CPU 端设置一次,着色器内所有顶点共享。in/out 类似于方法的入参和返回值。
坐标变换的完整链路长这样:
模型空间 -[Model]-> 世界空间 -[View]-> 观察空间 -[Projection]-> 裁剪空间 -[视口变换]-> 屏幕坐标
后面 1.5 节会详细讲每一步在做什么。
阶段 3:图元装配
把处理完的顶点组装成图元(Primitive)。最常用的是 GL_TRIANGLES——每三个顶点组成一个三角形。MC 里方块用的是 GL_QUADS(四边形,内部被拆成两个三角形)。
还有几种变体模式可以减少顶点数据:
TRIANGLES: v0,v1,v2 | v3,v4,v5 (6顶点画2三角形)
STRIP: v0,v1,v2 | v1,v2,v3 (4顶点画2三角形,复用 v1 v2)
阶段 4:光栅化
光栅化是管线里概念跨度最大的一步。在此之前处理的都是离散的顶点(向量),从这一步开始变成连续的像素区域。
光栅化做两件事:
覆盖判定:确定屏幕上哪些像素被这个三角形覆盖
插值:三角形三个顶点各带一份数据(颜色 UV 等),内部像素的值按重心坐标做加权平均
覆盖判定的原理
GPU 遍历三角形包围盒内的每个像素中心点,用边方程(Edge Function) 判断该点是否在三角形内部。对三角形的三条边分别计算:
edge(A, B, P) = (B.x - A.x) * (P.y - A.y) - (B.y - A.y) * (P.x - A.x)
如果三条边方程结果符号一致(全正或全负),点 P 在三角形内部。这个判定完全是乘法和减法,GPU 可以大规模并行。
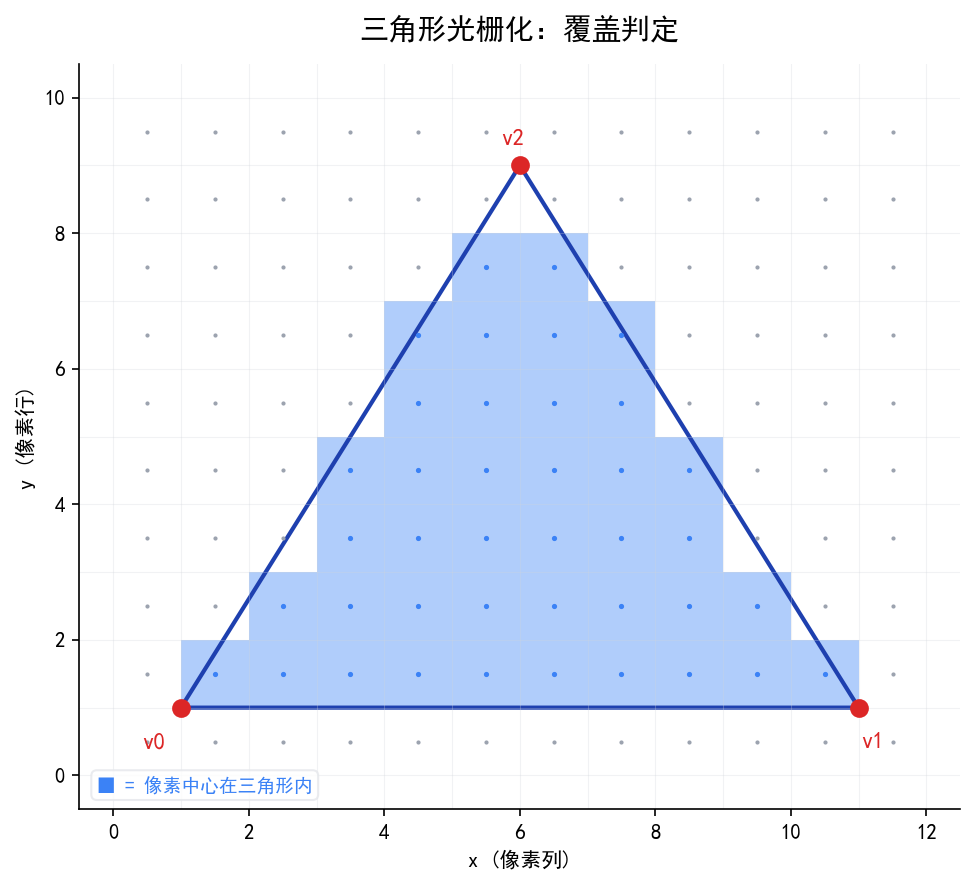
这张图展示了一个三角形在像素网格上的覆盖判定结果——蓝色填充的方格是像素中心落在三角形内部的像素。
重心坐标插值
确定一个像素在三角形内部后,需要算它的属性值(颜色 UV 等)。使用重心坐标(Barycentric Coordinates):
三角形内任意点 P 都可以表示为三个顶点的加权组合:
P = w0 * V0 + w1 * V1 + w2 * V2
其中 w0 + w1 + w2 = 1, w0 >= 0, w1 >= 0, w2 >= 0
权重 w0 w1 w2 就是重心坐标。用同样的权重对顶点属性插值:
color_P = w0 * color_V0 + w1 * color_V1 + w2 * color_V2
uv_P = w0 * uv_V0 + w1 * uv_V1 + w2 * uv_V2
这就是为什么三个顶点设不同颜色,中间会自动出现渐变。光栅化硬件每秒可以处理数十亿次这样的插值。
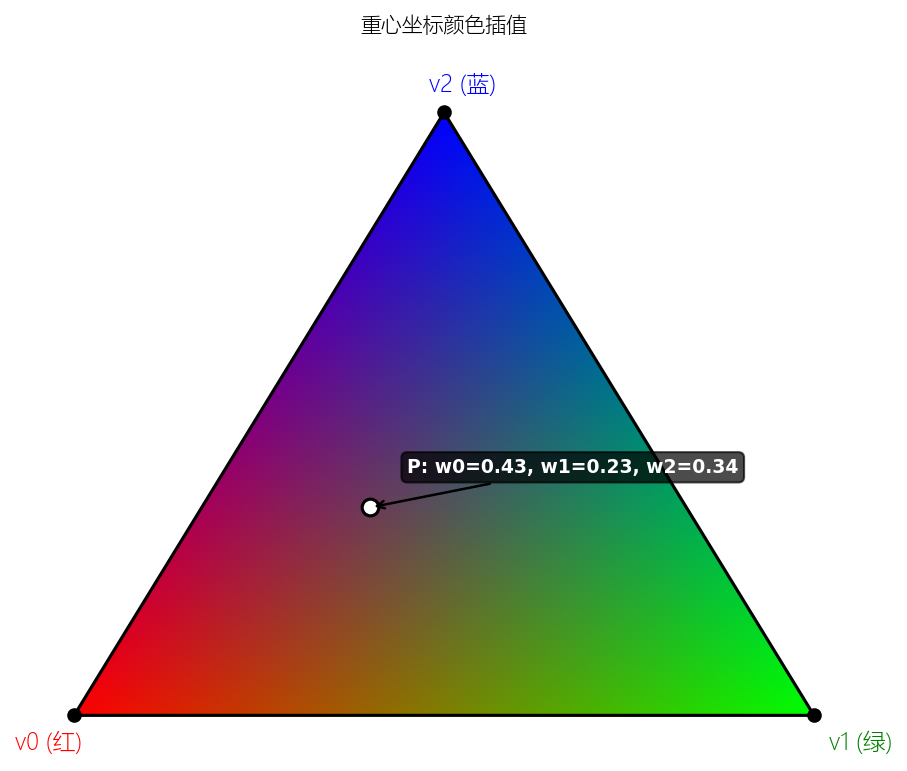
这张图展示了重心坐标插值的效果——三个顶点分别设为红 绿 蓝,三角形内部的每个像素根据其到三个顶点的距离权重得到混合色。
透视校正插值
上面的插值公式在正交投影下是精确的,但在透视投影下会出问题——远处的像素和近处的像素在屏幕上看起来一样大,但在 3D 空间里跨越的距离不同。
解决方法是透视校正插值:不直接插值属性值,而是先除以深度 z 做插值,再乘回来。GPU 硬件自动处理这个,着色器里不需要手动做。但理解这个概念能解释为什么有些老游戏的纹理在斜面上会"游动"——它们没做透视校正。
插值的效果就是渐变。顶点 A 是红色 顶点 B 是绿色,AB 中点的颜色就是黄色。这就是为什么一个只有三个顶点颜色信息的三角形能显示出平滑渐变。
阶段 5:片段着色器(可编程)
对每个片段执行一次。片段可以理解为"候选像素"——光栅化产生的每个被覆盖的像素位置都会生成一个片段。
片段着色器的核心任务:决定这个像素最终是什么颜色。
#version 150
in vec4 vertexColor; // 从顶点着色器传来(已被光栅化插值)
in vec2 texCoord; // 纹理坐标(已插值)
uniform sampler2D Sampler0; // 纹理采样器
out vec4 fragColor; // 最终颜色输出
void main() {
// 从纹理图上取色
vec4 texColor = texture(Sampler0, texCoord);
// 纹理色 × 顶点色 = 最终色
fragColor = texColor * vertexColor;
}
这就是 .fsh 文件的内容。sampler2D 是纹理的句柄,texture() 函数根据 UV 坐标从纹理图上采样得到颜色。
片段 vs 像素:同一个屏幕位置可能有多个片段重叠(半透明玻璃后面还有方块),后续的测试阶段决定最终哪个片段胜出。
阶段 6:测试与混合
片段不能直接写入画面,要过几道检查:
深度测试(Depth Test) — 解决遮挡问题。GPU 维护一个和屏幕同大小的深度缓冲,记录每个像素位置目前最近物体的深度值。新片段更近就覆盖,更远就丢弃。不依赖绘制顺序。
模板测试(Stencil Test) — 用一个 mask 控制哪些区域可以渲染。描边效果 镜面反射会用到。
混合(Blending) — 处理半透明。经典 alpha 混合公式:
最终颜色 = 新颜色 × alpha + 旧颜色 × (1 - alpha)
MC 里的玻璃 水面 粒子效果都依赖混合。但混合有个坑:半透明物体必须从远到近排序后绘制,否则结果不对。这是 MC 水面偶尔闪烁的原因之一。
阶段 7:帧缓冲
最终颜色写入帧缓冲。帧缓冲就是一块 width × height × 4(RGBA)的内存区域。渲染完毕后,帧缓冲内容被交换到前台显示——这就是"双缓冲"机制,避免画面撕裂。
哪些阶段你能控制
光影包之所以能改变 MC 的画面风格,本质就是替换了顶点着色器和片段着色器的代码。管线的固定阶段不变,但可编程阶段的逻辑完全由你说了算。
1.3 顶点与顶点属性
上一节我们知道管线的输入是"顶点数据"。但这个数据到底长什么样?怎么存储?怎么告诉 GPU 如何解析?这一节搞清楚。
顶点不只是一个坐标
做后端的同学可以把顶点理解为一条数据库记录——它不只有 position 字段,还带着 color UV normal 等多个字段。GPU 需要的不是"一个点",而是渲染这个点所需的全部信息。
MC 最新源码里 VertexFormatElement 定义了所有可能的字段:
// com.mojang.blaze3d.vertex.VertexFormatElement
public static final VertexFormatElement POSITION = register(0, 0, Type.FLOAT, false, 3); // xyz 三个 float
public static final VertexFormatElement COLOR = register(1, 0, Type.UBYTE, true, 4); // rgba 四个 unsigned byte
public static final VertexFormatElement UV0 = register(2, 0, Type.FLOAT, false, 2); // 主纹理坐标 uv
public static final VertexFormatElement UV1 = register(3, 1, Type.SHORT, false, 2); // 覆盖层坐标(受伤变红)
public static final VertexFormatElement UV2 = register(4, 2, Type.SHORT, false, 2); // 光照贴图坐标
public static final VertexFormatElement NORMAL = register(5, 0, Type.BYTE, true, 3); // 法线方向 xyz
register(id, index, type, normalized, count) 五个参数分别是:全局编号 同类型下标 数据类型 是否归一化 分量个数。
这里有个细节:COLOR 用 UBYTE 而不是 FLOAT,4 个 byte 只占 4 字节,而 4 个 float 要占 16 字节。normalized = true 意味着 GPU 读取时会自动把 0-255 映射到 0.0-1.0。用整型存颜色是图形学里常见的省显存做法。
MC 的顶点格式
不同渲染对象需要的字段不同。MC 用 DefaultVertexFormat 预定义了若干格式:
// 方块渲染格式:位置 + 颜色 + 纹理坐标 + 光照
public static final VertexFormat BLOCK = VertexFormat.builder()
.add("Position", VertexFormatElement.POSITION) // 3×float = 12 bytes
.add("Color", VertexFormatElement.COLOR) // 4×ubyte = 4 bytes
.add("UV0", VertexFormatElement.UV0) // 2×float = 8 bytes
.add("UV2", VertexFormatElement.UV2) // 2×short = 4 bytes
.build(); // 总计 28 bytes/顶点
// 实体渲染格式:比方块多了覆盖层和法线
public static final VertexFormat ENTITY = VertexFormat.builder()
.add("Position", VertexFormatElement.POSITION)
.add("Color", VertexFormatElement.COLOR)
.add("UV0", VertexFormatElement.UV0)
.add("UV1", VertexFormatElement.UV1) // 覆盖层(受伤闪红)
.add("UV2", VertexFormatElement.UV2)
.add("Normal", VertexFormatElement.NORMAL) // 法线(光照计算)
.padding(1) // 对齐填充
.build();
// GUI / HUD 格式:最精简
public static final VertexFormat POSITION_TEX_COLOR = VertexFormat.builder()
.add("Position", VertexFormatElement.POSITION)
.add("UV0", VertexFormatElement.UV0)
.add("Color", VertexFormatElement.COLOR)
.build();
格式越精简 每个顶点占字节越少 传输和处理越快。GUI 不需要光照和法线,所以用最小格式即可。
内存布局:交错存储
MC 用的是交错布局(Interleaved)——同一个顶点的所有字段连续存放:
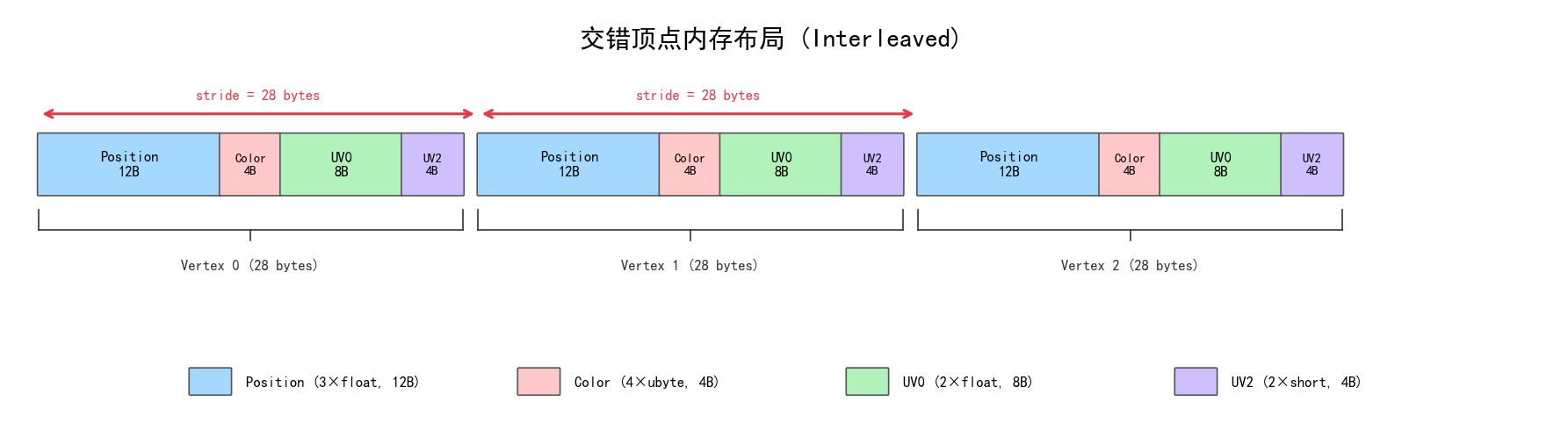
好处是 cache 友好——GPU 处理一个顶点时需要读它的全部字段,交错布局让这些字段在内存上紧挨着。做后端的同学可以类比"行存储"——一行记录的所有列放在一起,适合读整行。
另一种是分离布局(所有 position 连续,所有 color 连续),类似"列存储",适合只读部分字段的场景。MC 不用这种。
VBO:顶点缓冲对象
VBO(Vertex Buffer Object) 是 GPU 显存上的一块缓冲区,存放顶点数据。
在 MC 1.14 之前的"立即模式"里,每一帧都要从 CPU 内存把顶点数据搬运到 GPU——类似每次请求都建一个新的数据库连接。VBO 的做法是一次性上传到显存,后续直接复用——类似连接池。
MC 里 BufferBuilder 就是在 CPU 端攒数据,攒完调 build() 打包成 MeshData,再上传到 GPU 的 GpuBuffer。
VAO:顶点数组对象
VBO 里存的只是一堆原始字节。GPU 不知道"从第 0 字节开始的 12 个字节是 3 个 float 代表位置"这件事。
VAO(Vertex Array Object) 就是用来描述这个解析规则的——哪个字段从哪个偏移开始 多少字节 什么数据类型 步长是多少。
类比:VBO 是 CSV 文件的原始内容,VAO 是表头(schema)。有了 schema GPU 才知道怎么切分字段。
MC 源码里 VertexFormat.getOffsetsByElement() 返回的就是每个 element 在一个顶点内的字节偏移量。
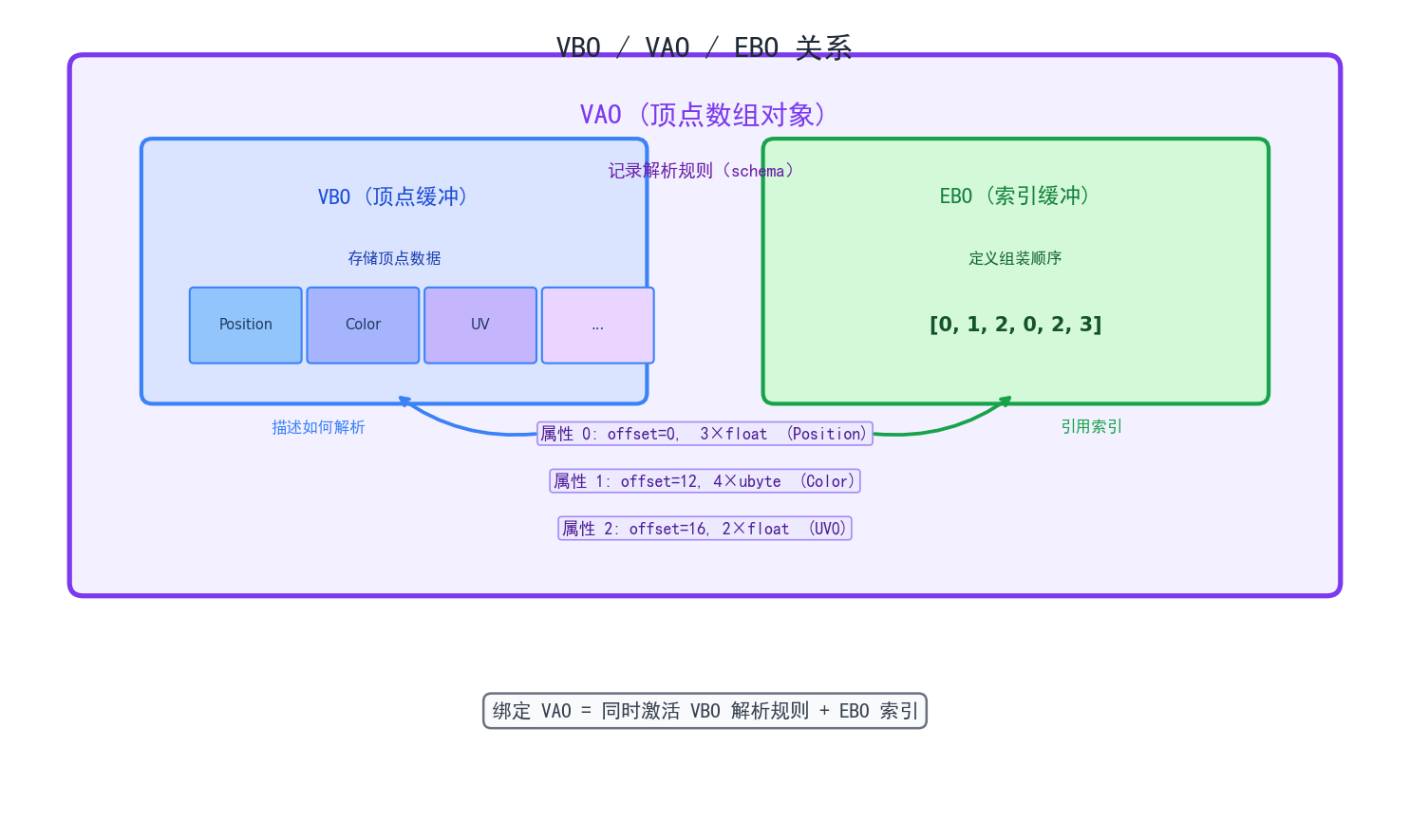
这张图展示了三者的关系——VAO 是 schema(描述解析规则),VBO 是原始数据(顶点字节流),EBO 是索引(定义顶点组装顺序)。
索引缓冲(EBO/IBO)
画一个正方形需要两个三角形 6 个顶点,但其中 2 个顶点是重复的(对角线两端)。索引缓冲的做法是:只存 4 个独立顶点,用索引数组 [0,1,2, 0,2,3] 指定组合方式。
对大规模场景(一个区块几万个面),索引复用能省掉大量重复顶点数据。MC 的 BufferBuilder 内部用 VertexFormat.Mode.indexCount() 自动计算索引数量。
数据流总结
CPU 端 BufferBuilder 攒顶点 -> build() 打包 MeshData -> 上传到 GpuBuffer(VBO)
GPU 端按 VertexFormat(VAO schema) 解析 -> 喂给顶点着色器
1.4 着色器与 GLSL
管线里有两个可编程阶段:顶点着色器和片段着色器。编写它们用的语言叫 GLSL(OpenGL Shading Language),语法很像 C,但内置了向量和矩阵运算。
着色器是什么
本质上着色器就是一段运行在 GPU 上的函数。GPU 对每个顶点/片段并行调用这个函数,输入是该顶点/片段的数据,输出是变换后的坐标或颜色。
MC 的着色器文件通过 ShaderType 枚举区分类型:
// com.mojang.blaze3d.shaders.ShaderType
public enum ShaderType {
VERTEX("vertex", ".vsh"), // 顶点着色器
FRAGMENT("fragment", ".fsh"); // 片段着色器
}
着色器源码存放在资源包的 shaders/ 目录下,由 ShaderManager 在资源加载时编译。
GLSL 数据类型速查
做后端的同学把这些当成"GPU 上的基本类型"理解即可:
// 标量——和 Java 基本类型对应
float f = 3.14; // 单精度浮点
int i = 42; // 整数
bool b = true; // 布尔
// 向量——打包的多分量类型,GPU 一条指令处理整个向量
vec2 uv = vec2(0.5, 0.5); // 2 个 float(纹理坐标)
vec3 position = vec3(1.0, 2.0, 3.0); // 3 个 float(空间坐标)
vec4 color = vec4(1.0, 0.0, 0.0, 1.0); // 4 个 float(RGBA 颜色)
// 矩阵——用于坐标变换
mat4 transform; // 4×4 矩阵
// 采样器——纹理的句柄
sampler2D tex; // 2D 纹理
向量有个很实用的语法叫 Swizzle——任意重排分量:
vec4 c = vec4(1.0, 0.5, 0.0, 1.0);
c.rgb // vec3(1.0, 0.5, 0.0) 取前三个分量
c.bgr // vec3(0.0, 0.5, 1.0) 反转 RGB
c.rrrr // vec4(1.0, 1.0, 1.0, 1.0) 广播
c.xy // vec2(1.0, 0.5)
分量有三套等价的访问名:xyzw(坐标)= rgba(颜色)= stpq(纹理坐标),用哪套只看语义清晰度。
变量限定符
GLSL 通过限定符区分数据的来源和去向:
// in — 输入,从上游接收
in vec3 Position; // 顶点着色器里:来自顶点数据
in vec4 vertexColor; // 片段着色器里:来自顶点着色器(已插值)
// out — 输出,传给下游
out vec4 vertexColor; // 顶点着色器里:传给片段着色器
out vec4 fragColor; // 片段着色器里:最终像素颜色
// uniform — 全局只读常量,CPU 端设置,一次 draw call 内不变
uniform mat4 ModelViewMat; // 变换矩阵
uniform mat4 ProjMat; // 投影矩阵
uniform float GameTime; // 游戏时间
uniform sampler2D Sampler0; // 纹理
做后端类比:in 是方法参数,out 是返回值,uniform 是注入的全局配置(类似 Spring 的 @Value)。
内置变量
GLSL 有一些特殊的内置变量,不需要声明直接使用:
// ===== 顶点着色器 =====
gl_Position // (必须设置) 变换后的顶点位置,vec4
gl_PointSize // 点的大小,用于 GL_POINTS 模式
gl_VertexID // 当前顶点的索引号
// ===== 片段着色器 =====
gl_FragCoord // 当前片段的屏幕坐标,vec4 (x, y, z, 1/w)
gl_FrontFacing // 是否是正面,bool
gl_FragDepth // 可选:手动设置片段深度(覆盖默认值)
gl_FragCoord.xy 在后处理着色器里很有用——可以拿到当前像素的屏幕位置做全屏效果。
向量构造与运算
向量的构造方式非常灵活:
// 各种构造方式
vec4 a = vec4(1.0); // (1.0, 1.0, 1.0, 1.0) 广播标量
vec4 b = vec4(vec3(1.0, 2.0, 3.0), 1.0); // 从 vec3 + float 构造
vec3 c = vec3(vec2(1.0, 2.0), 3.0); // 从 vec2 + float 构造
vec2 d = vec4(1.0, 2.0, 3.0, 4.0).xy; // 从 vec4 截取
// 向量运算——逐分量进行
vec3 a = vec3(1.0, 2.0, 3.0);
vec3 b = vec3(4.0, 5.0, 6.0);
vec3 c = a + b; // (5.0, 7.0, 9.0) 逐分量加
vec3 d = a * b; // (4.0, 10.0, 18.0) 逐分量乘(不是点积!)
vec3 e = a * 2.0; // (2.0, 4.0, 6.0) 标量乘
// 矩阵 × 向量
mat4 M = ...;
vec4 result = M * vec4(position, 1.0); // 矩阵乘法
常用内置函数
GLSL 内置了大量数学函数,GPU 对它们做了硬件级优化——这些不是库函数,是直接映射到 GPU 指令的。
基础数学函数
// 取值
abs(x) // 绝对值
sign(x) // 符号 (-1.0, 0.0, 1.0)
floor(x) // 向下取整
ceil(x) // 向上取整
round(x) // 四舍五入
fract(x) // 小数部分 = x - floor(x)
mod(x, y) // 取模 = x - y * floor(x/y)
// 限制和插值
min(x, y) // 最小值
max(x, y) // 最大值
clamp(x, a, b) // 限制范围 [a, b],等价于 max(a, min(b, x))
mix(a, b, t) // 线性插值 = a * (1-t) + b * t
step(edge, x) // x < edge ? 0.0 : 1.0(硬切)
smoothstep(a, b, x) // 平滑 S 曲线插值(Hermite 插值)
// 三角函数
sin(x), cos(x), tan(x)
asin(x), acos(x), atan(x)
atan(y, x) // 二参数版本,返回完整 [-π, π] 范围
// 指数和幂
pow(x, y) // x 的 y 次方
exp(x) // e^x
exp2(x) // 2^x
log(x) // ln(x)
log2(x) // log₂(x)
sqrt(x) // 平方根
inversesqrt(x) // 1 / sqrt(x),GPU 有专用硬件,比手动除法快
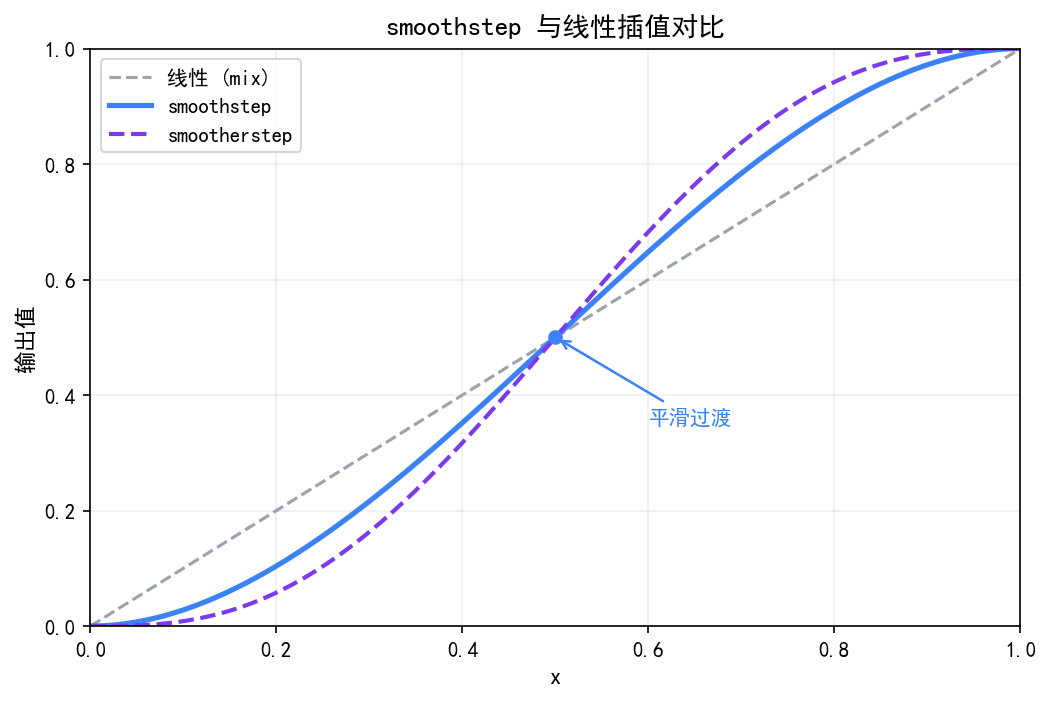
smoothstep 详解
smoothstep 是着色器里出现频率极高的函数,MC 的雾效就靠它。它做的事情是:
// smoothstep(edge0, edge1, x) 等价于:
float t = clamp((x - edge0) / (edge1 - edge0), 0.0, 1.0);
return t * t * (3.0 - 2.0 * t); // Hermite 插值多项式
效果是:x < edge0 时返回 0,x > edge1 时返回 1,中间是平滑的 S 曲线过渡(不是线性的)。比 mix + clamp 更自然。
向量专用函数
// 长度和距离
length(v) // 向量长度 = sqrt(dot(v, v))
distance(a, b) // 两点距离 = length(a - b)
normalize(v) // 归一化为单位向量 = v / length(v)
// 点积和叉积
dot(a, b) // 点积 = a.x*b.x + a.y*b.y + a.z*b.z
// 几何意义:|a|*|b|*cos(θ)
// 用途:光照计算(法线·光线方向 = 亮度因子)
cross(a, b) // 叉积(仅 vec3),结果垂直于 a 和 b
// 用途:计算面法线
// 反射和折射
reflect(I, N) // 反射向量,I 是入射方向,N 是法线
// = I - 2.0 * dot(N, I) * N
refract(I, N, eta) // 折射向量,eta 是折射率比
// 面朝向
faceforward(N, I, Nref) // 如果 dot(Nref, I) < 0 返回 N,否则返回 -N
点积的直觉理解:两个单位向量的点积等于它们夹角的余弦值。cos(0°)=1(同方向),cos(90°)=0(垂直),cos(180°)=-1(反方向)。光照计算里 dot(normal, lightDir) 就是这个原理——表面正对光源时最亮。
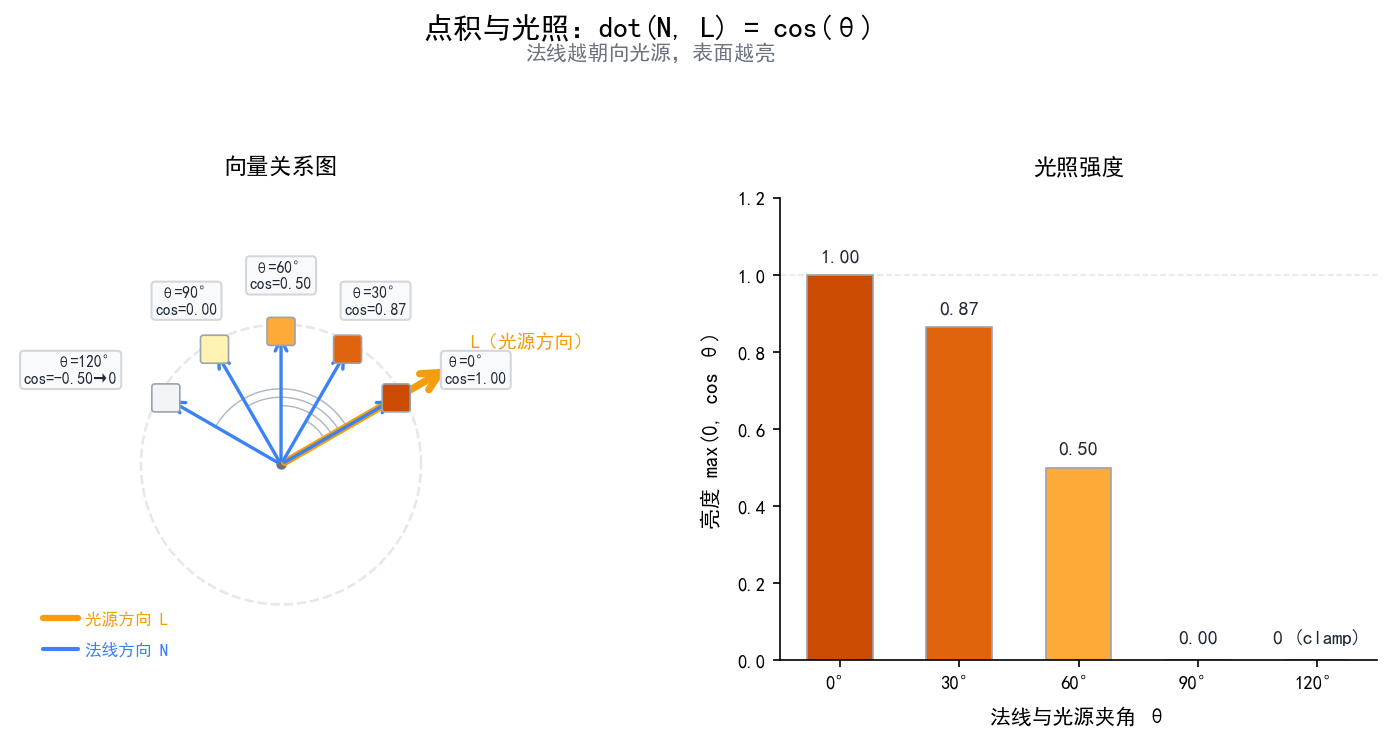
这张图展示了法线方向和光照强度的关系——dot(N, L) 的值直接决定了表面亮度。
纹理采样函数
// 基础采样
texture(sampler, uv) // 用浮点 UV 坐标采样,会做过滤(NEAREST 或 LINEAR)
texture(sampler, uv, bias) // 带 LOD 偏移的采样
// 精确像素采样
texelFetch(sampler, ivec2(x, y), lod) // 用整数坐标精确取某个像素,不做过滤
// MC 光照贴图用这个
// 纹理信息
textureSize(sampler, lod) // 返回 ivec2(width, height)
// Lod 相关
textureLod(sampler, uv, lod) // 手动指定 mipmap 级别采样
texture vs texelFetch 的区别:texture 用归一化的 [0,1] UV 坐标且会做过滤插值,texelFetch 用整数像素坐标且不做任何过滤——取哪个像素就是哪个像素。MC 的光照贴图是 16×16 的离散查找表,必须用 texelFetch 精确取值。
条件和比较函数
// 逐分量比较(返回 bvec)
lessThan(a, b) // a < b
greaterThan(a, b) // a > b
equal(a, b) // a == b
// 逐分量选择
mix(a, b, bvec) // bvec 版本的 mix:按 bool 向量选择
常见着色器技巧
补充几个在 MC 着色器里经常见到的手法:
// 1. 丢弃透明片段
if (texColor.a < 0.01) discard; // 不写入任何缓冲
// 2. 颜色空间转换:线性 -> sRGB(伽马校正)
vec3 srgb = pow(linearColor, vec3(1.0 / 2.2));
// 3. 雾效(MC 标准做法)
float fogFactor = smoothstep(FogStart, FogEnd, vertexDistance);
color = mix(color, FogColor, fogFactor * FogColor.a);
// 4. 法线贴图解包(-1~1 范围)
vec3 normal = texture(normalMap, uv).xyz * 2.0 - 1.0;
// 5. 亮度计算(人眼感知加权)
float luminance = dot(color.rgb, vec3(0.2126, 0.7152, 0.0722));
// 6. 边缘发光(Fresnel 效果)
float rim = 1.0 - max(dot(normal, viewDir), 0.0);
rim = pow(rim, 3.0);
color += rimColor * rim;
MC 着色器实例:方块渲染
首先是顶点着色器(简化版):
#version 150
in vec3 Position;
in vec4 Color;
in vec2 UV0;
in ivec2 UV2;
uniform mat4 ModelViewMat;
uniform mat4 ProjMat;
uniform sampler2D Sampler2; // 光照贴图
out vec4 vertexColor;
out vec2 texCoord0;
out float vertexDistance;
void main() {
// 坐标变换
gl_Position = ProjMat * ModelViewMat * vec4(Position, 1.0);
// 算到相机的距离(雾效用)
vertexDistance = length((ModelViewMat * vec4(Position, 1.0)).xyz);
// 透传纹理坐标
texCoord0 = UV0;
// 查光照贴图得到亮度
vec4 lightColor = texelFetch(Sampler2, UV2 / 16, 0);
vertexColor = Color * lightColor;
}
然后是片段着色器:
#version 150
in vec4 vertexColor;
in vec2 texCoord0;
in float vertexDistance;
uniform sampler2D Sampler0; // 方块纹理
uniform vec4 ColorModulator;
uniform float FogStart;
uniform float FogEnd;
uniform vec4 FogColor;
out vec4 fragColor;
void main() {
// 采样方块纹理
vec4 texColor = texture(Sampler0, texCoord0);
// 透明像素直接丢弃,不写入帧缓冲
if (texColor.a < 0.01) discard;
// 纹理色 × 顶点色(含光照) × 全局调色
vec4 color = texColor * vertexColor * ColorModulator;
// 应用雾效:距离越远越接近雾色
float fogFactor = smoothstep(FogStart, FogEnd, vertexDistance);
color = mix(color, FogColor, fogFactor * FogColor.a);
fragColor = color;
}
discard 关键字很特殊——直接抛弃这个片段,连深度缓冲都不写。MC 用它处理纹理中的透明部分(比如树叶的空隙)。
MC 着色器文件组织
MC 的着色器源文件在资源包 assets/minecraft/shaders/ 下组织:
shaders/
├── core/ 核心着色器(方块 实体 粒子 GUI 天空)
├── include/ 公共代码片段(雾效函数 光照工具)
└── post/ 后处理着色器(模糊 辉光 反色)
MC 着色器管线的演进
早期版本(1.17~1.20)每个着色器由 .json(声明 uniform 和采样器绑定)+ .vsh + .fsh 三个文件组成。但在 1.21.4 的渲染重构之后,MC 不再用 json 描述核心渲染管线——着色器的绑定 混合模式 深度状态 顶点格式等全部在 Java 代码里用 Builder 模式硬编码:
// net.minecraft.client.renderer.RenderPipelines(简化)
// 方块地形管线
private static final RenderPipeline.Snippet TERRAIN_SNIPPET = RenderPipeline.builder(GENERIC_BLOCKS_SNIPPET)
.withUniform("Projection", UniformType.UNIFORM_BUFFER)
.withUniform("ChunkSection", UniformType.UNIFORM_BUFFER)
.withVertexShader("core/terrain") // 着色器路径直接写死
.withFragmentShader("core/terrain")
.buildSnippet();
// 实体管线
private static final RenderPipeline.Snippet ENTITY_SNIPPET = RenderPipeline.builder(MATRICES_FOG_LIGHT_DIR_SNIPPET)
.withVertexShader("core/entity")
.withFragmentShader("core/entity")
.withSampler("Sampler0") // 纹理采样器
.withSampler("Sampler2") // 光照贴图
.withVertexFormat(DefaultVertexFormat.ENTITY, VertexFormat.Mode.QUADS)
.withDepthStencilState(DepthStencilState.DEFAULT)
.buildSnippet();
这种做法的好处是编译期类型安全——管线配置不再有运行时 json 解析错误的可能。但也意味着资源包不能像以前那样通过修改 json 来切换着色器了。
例外:后处理管线(PostChain)仍然用 json 配置。 PostChainConfig 通过 Codec 反序列化 json 文件来构建后处理 pass 链:
// net.minecraft.client.renderer.PostChainConfig
public record PostChainConfig(
Map<Identifier, InternalTarget> internalTargets,
List<Pass> passes
) {
public record Pass(
Identifier vertexShaderId, // 顶点着色器 ID
Identifier fragmentShaderId, // 片段着色器 ID
List<Input> inputs, // 输入纹理/目标
Identifier outputTarget, // 输出目标
Map<String, List<UniformValue>> uniforms
) { ... }
}
所以总结:核心渲染管线(方块 实体 粒子 GUI)的配置在 Java 代码中硬编码(RenderPipelines.java),后处理管线(模糊 发光描边 反色等)仍由 json 驱动(PostChainConfig)。着色器源文件(.vsh .fsh)本身还是放在资源包 shaders/ 目录下,只是"谁用哪个着色器 配合什么状态"这件事不再写在 json 里。
1.5 矩阵变换
着色器里频繁出现的 ProjMat * ModelViewMat * vec4(Position, 1.0) 到底在做什么?这一节讲清楚坐标变换的数学原理——不需要线性代数基础,从直觉出发。
为什么用矩阵
3D 渲染需要对顶点做平移 旋转 缩放 投影。这些操作都可以表示为矩阵乘法,而矩阵乘法有个好处:多次变换可以合并成一次乘法。
不合并:对每个顶点做 3 次变换 = 3 次矩阵乘法
合并后:先算 M = A × B × C,再对每个顶点乘一次 M
一个场景几十万个顶点,合并后只算一次就省了几十万次乘法。GPU 的矩阵乘法还有硬件加速,所以矩阵是图形学的核心数据结构。
齐次坐标:解决平移问题
旋转和缩放都是线性变换,可以用 3×3 矩阵表示。但平移不是线性变换——(x+1, y+2, z+3) 没法写成 3×3 矩阵乘 (x, y, z) 的形式。
解决方案是升维:在三维坐标后面加一个 w 分量,变成 4 维的齐次坐标 (x, y, z, w)。这样 4×4 矩阵就能统一表示平移 旋转 缩放。
位置点:w = 1,受平移影响 (x, y, z, 1)
方向向量:w = 0,不受平移 (dx, dy, dz, 0)
这就是着色器里 vec4(Position, 1.0) 的由来——把 3D 位置扩展为齐次坐标。
基础变换矩阵
三种基础变换的 4×4 矩阵形式。做后端的同学不需要背这些公式,理解它们的结构即可——实际开发中调库就行。
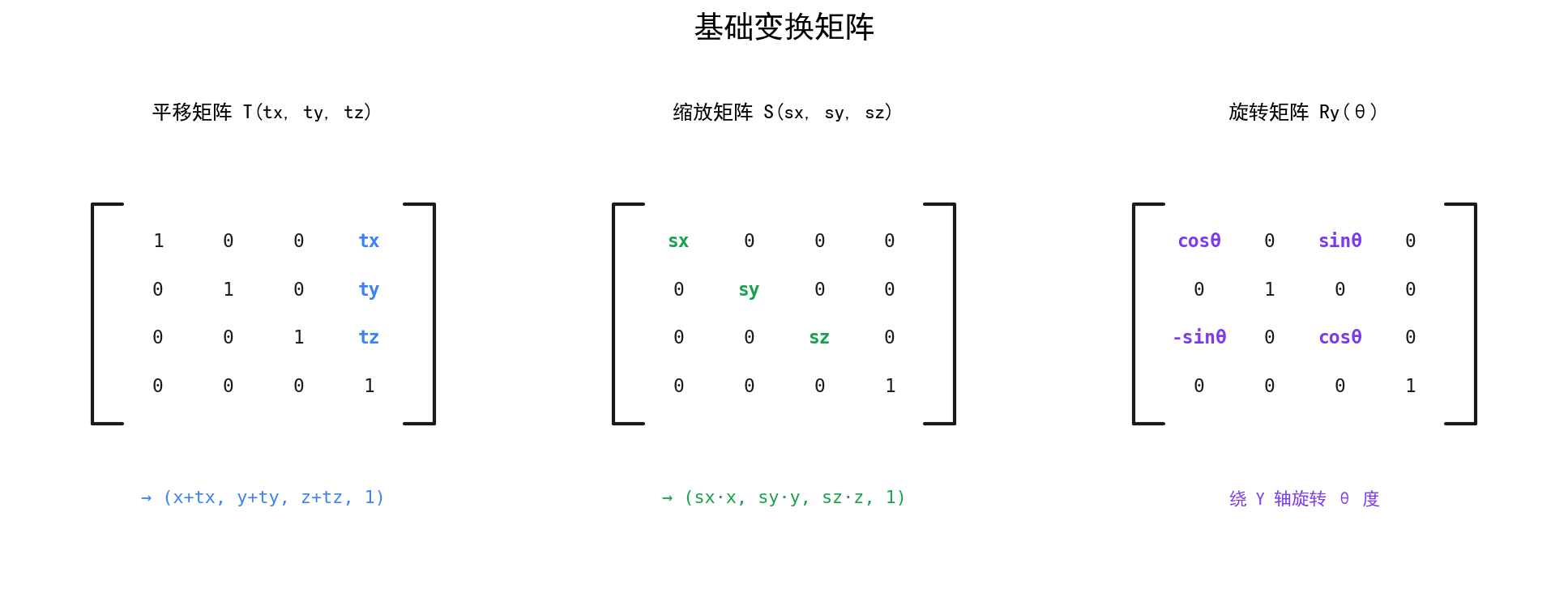
平移矩阵的平移量放在第四列。注意如果 w=0(方向向量),平移不生效——这就是齐次坐标的精妙之处。
缩放矩阵的缩放因子放在对角线上。等比缩放 sx=sy=sz,非等比缩放三者不同。
旋转矩阵由 sin/cos 构成。MC 里用四元数(Quaternion)表示旋转更常见——避免万向锁问题,PoseStack.mulPose(Quaternionfc) 接收的就是四元数。
组合变换:多个变换通过矩阵乘法组合,最终矩阵 = 平移 × 旋转 × 缩放。
矩阵乘法不满足交换律——先旋转再平移 vs 先平移再旋转,结果完全不同。从右往左读:先缩放 再旋转 最后平移。
五个坐标空间

这张图回答一个问题:一个顶点从模型到屏幕要经过哪些坐标变换。
一个顶点要经过五个空间:
模型空间(Local) — 模型自身的坐标系,原点在模型中心。比如一把剑的所有顶点都相对剑的中心定义。
世界空间(World) — 游戏世界的全局坐标系。Model 矩阵负责把模型放到世界中的正确位置(平移 + 旋转 + 缩放)。
观察空间(View) — 以摄像机为原点的坐标系。View 矩阵本质是摄像机变换的逆——把整个世界反向移动,使摄像机回到原点。
裁剪空间(Clip) — Projection 矩阵把 3D 空间压缩到一个标准立方体 [-1, 1]³ 内。超出范围的顶点会被裁剪掉。
屏幕空间(Screen) — 最终的像素坐标 (0,0) 到 (width, height)。由 GPU 自动完成视口变换。
MC 里的 PoseStack
MC 用 PoseStack 管理变换矩阵。它内部是一个栈结构,每个栈帧是一个 Pose——包含 4×4 位姿矩阵和 3×3 法线矩阵:
// com.mojang.blaze3d.vertex.PoseStack.Pose
public static final class Pose {
private final Matrix4f pose = new Matrix4f(); // 位姿矩阵(平移旋转缩放)
private final Matrix3f normal = new Matrix3f(); // 法线矩阵(光照计算用)
private boolean trustedNormals = true; // 法线矩阵是否可信
}
使用方式:
poseStack.pushPose(); // 保存当前状态
poseStack.translate(x, y, z); // 平移
poseStack.mulPose(Axis.YP.rotationDegrees(rotation)); // 绕 Y 轴旋转
poseStack.scale(sx, sy, sz); // 缩放
// 渲染...
poseStack.popPose(); // 恢复之前的状态
pushPose/popPose 的作用就像 Git 的 stash/pop——保存现场 做操作 恢复现场。这在渲染树状层级结构时很有用:渲染手臂时 push,在手臂坐标系下渲染手掌和武器,完了 pop 回躯干继续渲染其他部位。
Model 矩阵
把模型从自身坐标系放到世界中。包含平移(放哪里)旋转(朝哪边)缩放(多大)。
MC 里 Model 矩阵通过 PoseStack 上的 translate/mulPose/scale 累乘构建。
View 矩阵
把世界坐标系转换为摄像机坐标系。MC 中"摄像机"就是玩家的眼睛位置和朝向。
实际上 MC 把 Model 和 View 合并成一个 ModelViewMat 传给着色器:
ModelViewMat = View × Model
Projection 矩阵
把 3D 空间投影到 2D 平面。两种模式:
透视投影 — 近大远小,模拟人眼。MC 的游戏画面用透视投影,参数包含 FOV(视野角) 宽高比 近/远裁剪面。
正交投影 — 没有近大远小效果,平行线保持平行。MC 的 GUI 物品栏 和 F5 第三人称的小地图用正交投影。
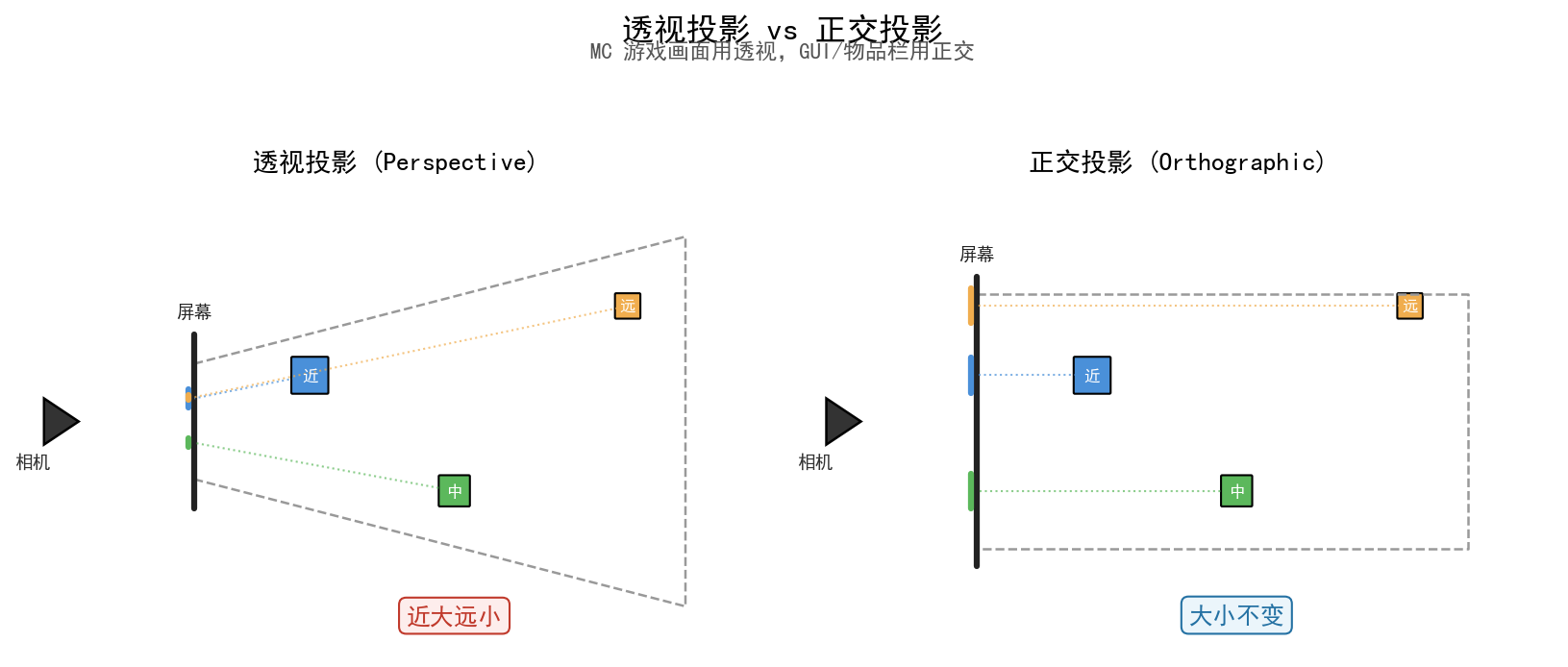
这张图展示了两种投影方式的视觉差异——透视投影的视锥体让远处物体缩小,正交投影的矩形体保持物体大小不变。
MVP 合并
着色器里那行代码的完整含义:
gl_Position = ProjMat * ModelViewMat * vec4(Position, 1.0);
// 投影 模型视图 齐次坐标扩展
矩阵乘法从右往左读:先把顶点放到世界里(Model),再转到摄像机视角(View),最后投影到屏幕(Projection)。
法线矩阵
法线是垂直于表面的方向向量,光照计算依赖它。但法线不能直接用 Model 矩阵变换——非等比缩放会导致法线不再垂直于表面。
正确做法是:法线矩阵 = Model 矩阵左上 3×3 部分的逆转置。MC 里 PoseStack.Pose 的 computeNormalMatrix() 就是这么算的:
private void computeNormalMatrix() {
this.normal.set(this.pose).invert().transpose();
this.trustedNormals = false;
}
trustedNormals 标记在等比缩放时为 true(此时 normal 矩阵退化为旋转矩阵不需要逆转置),非等比缩放时为 false(必须走完整计算)。这是一个性能优化——大多数情况下缩放都是等比的。
1.6 纹理系统
最后一块拼图。着色器里的 texture(Sampler0, texCoord) 到底做了什么?纹理怎么从一张 PNG 变成 GPU 能用的数据?
纹理是什么
纹理就是贴在模型表面的图片。没有纹理,一个方块只是一个纯色的立方体;有了纹理,它看起来像泥土 石头 木板。纹理让简单的几何体拥有丰富的视觉细节,而不需要增加顶点数量。
做后端类比:纹理就像数据库里的 BLOB 字段——存储二维像素数据,通过坐标索引取值。
UV 坐标
UV 坐标定义了顶点和纹理图片之间的映射关系。之所以叫 UV 而不是 XY,是因为 XYZ 已经被 3D 空间坐标占了。
UV 坐标范围 [0, 1]:(0, 0) 对应纹理左上角,(1, 1) 对应右下角。MC 加载纹理时做了 Y 轴翻转以适配 OpenGL 的坐标惯例。
纹理图集(Atlas)
MC 不是给每个方块单独一张纹理——而是把所有方块纹理拼到一张大图上,叫纹理图集。
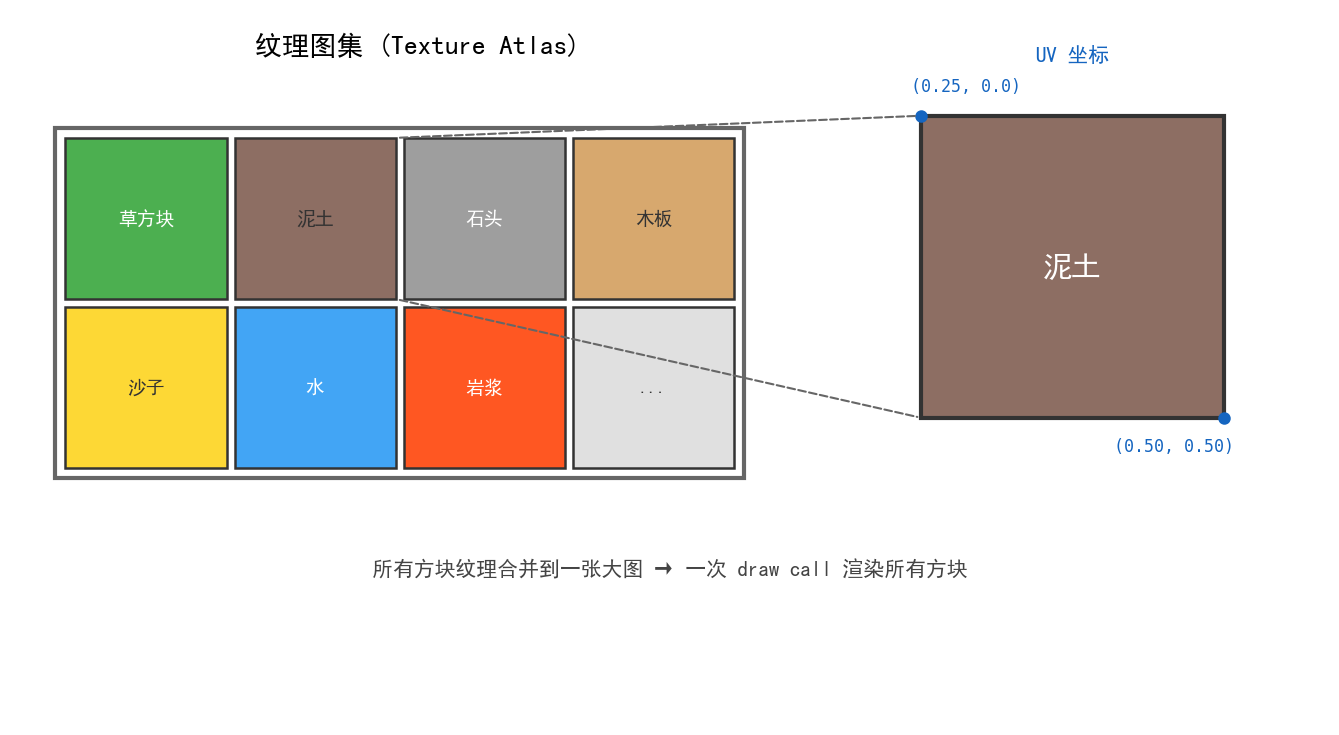
渲染某个方块时,UV 坐标不是 (0,0)-(1,1) 而是图集中对应区域的 UV 范围。好处是减少纹理切换——切换纹理对 GPU 来说是一次开销较大的状态变更,把所有方块合到一张图上可以一个 draw call 画完所有方块。
做后端类比:合并小请求为批量请求减少网络往返,道理一样。
纹理过滤
纹理被放大或缩小时如何采样?MC 里由 FilterMode 控制:
// com.mojang.blaze3d.textures.FilterMode
public enum FilterMode {
NEAREST, // 最近邻:取最近像素,效果像素化锐利
LINEAR; // 线性插值:取周围像素加权平均,效果平滑模糊
}
MC 方块纹理用 NEAREST——保持像素风格是 Minecraft 美术风格的核心。如果用 LINEAR 方块表面会变糊。
缩小时还有 Mipmap 机制——预计算多级缩小版纹理,远处物体用小尺寸版本,避免闪烁和摩尔纹。MC 的"视频设置 -> Mipmap 等级"就是控制这个。GpuTexture 构造时通过 mipLevels 参数指定级数:
// com.mojang.blaze3d.textures.GpuTexture
public GpuTexture(int usage, String label, TextureFormat format,
int width, int height, int depthOrLayers, int mipLevels) {
// mipLevels: mip 级数,0 级是原图,每级尺寸减半
}
Mipmap 原理详解
Mipmap 是一组预计算的缩小版纹理链:
Level 0: 16×16 (原图)
Level 1: 8×8 (每 2×2 像素平均为 1 像素)
Level 2: 4×4
Level 3: 2×2
Level 4: 1×1
GPU 根据物体在屏幕上的大小自动选择合适的 mip 级别。远处的方块只占屏幕几个像素——如果用 Level 0 的 16×16 纹理采样,一个屏幕像素要"代表"纹理上多个像素,结果是闪烁噪点(欠采样)。用 Level 2 的 4×4 版本就不会有这个问题。
为什么叫 Mipmap?“Mip” 来自拉丁文 “multum in parvo”(小中见大)。额外显存开销是原纹理的 1/3(几何级数求和 1/4 + 1/16 + … ≈ 1/3)。
MC 里 mipLevels=4 意味着一个 16×16 的方块纹理会生成 4 级 mipmap,远处方块使用低级别版本渲染更平滑。
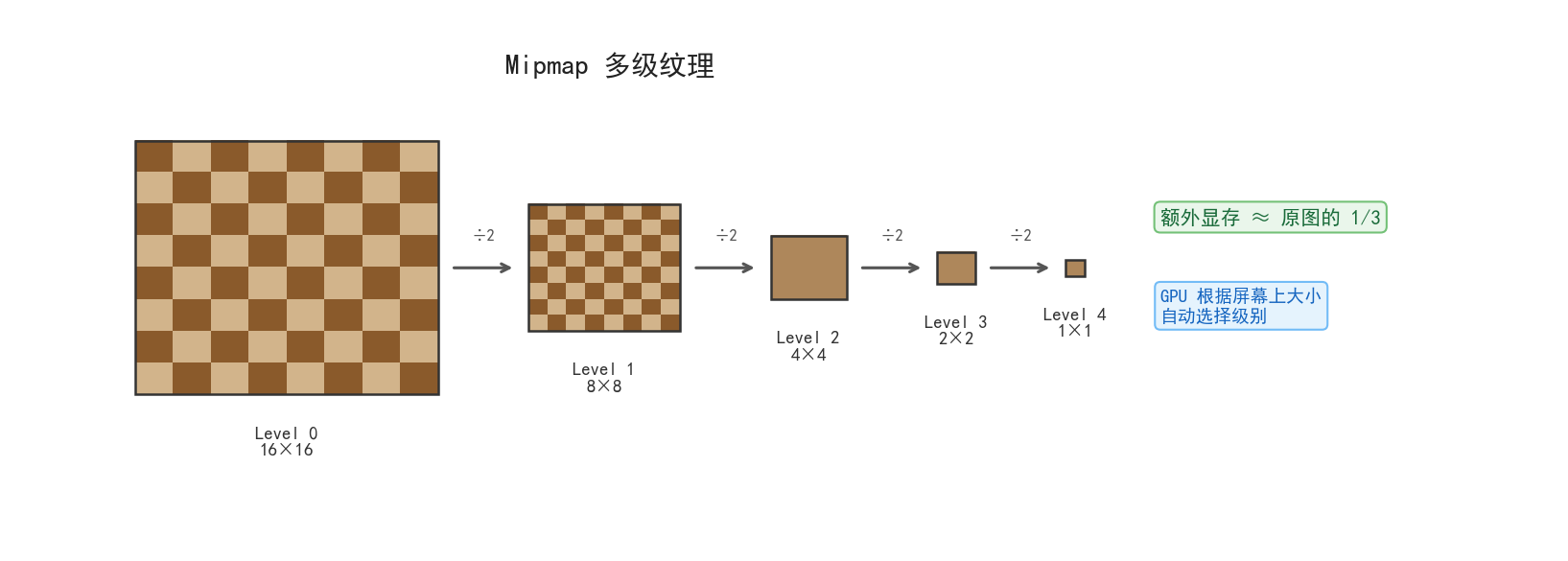
这张图展示了 Mipmap 各级别的实际效果——每级尺寸减半 细节越来越模糊,GPU 根据物体在屏幕上的大小自动选择合适的级别。
纹理环绕模式
UV 坐标超出 [0,1] 范围时怎么处理?由 AddressMode 控制:
// com.mojang.blaze3d.textures.AddressMode
public enum AddressMode {
REPEAT, // 重复平铺:UV=1.5 等效于 0.5
CLAMP_TO_EDGE; // 钳制到边缘:超出部分取边缘颜色
}
MC 方块纹理用 CLAMP_TO_EDGE(图集内不能重复平铺否则会采样到相邻方块纹理)。
纹理单元与采样器
GPU 可以同时绑定多张纹理。MC 着色器里的 Sampler 对应不同纹理单元:
uniform sampler2D Sampler0; // 纹理单元 0:主纹理(方块/实体贴图)
uniform sampler2D Sampler1; // 纹理单元 1:覆盖层(受伤变红效果)
uniform sampler2D Sampler2; // 纹理单元 2:光照贴图
光照贴图是个 16×16 像素的查找表——横轴是方块光等级(0-15),纵轴是天空光等级(0-15),每个像素存的是对应亮度的颜色乘数。着色器用 texelFetch(Sampler2, UV2 / 16, 0) 精确取某个光照等级的亮度值。
1.7 帧缓冲(Framebuffer)
到目前为止我们一直在说"渲染结果写入帧缓冲"。但帧缓冲到底是什么?能不能不直接画到屏幕上,而是画到一张"虚拟画布"上再做后处理?
默认帧缓冲
当你创建窗口时,系统自动给你一个默认帧缓冲——绑定到显示器输出。你往里写的颜色就是屏幕上看到的画面。
默认帧缓冲通常包含三个附件(Attachment):
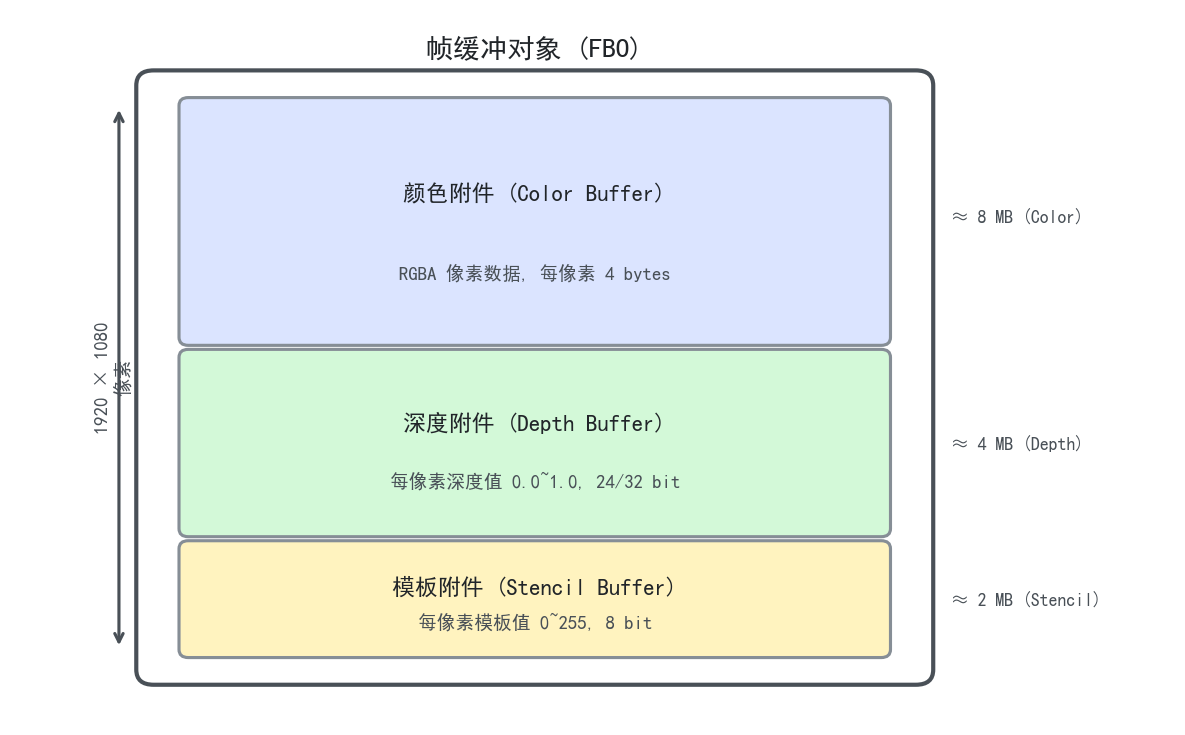
颜色附件存画面本身,深度附件做遮挡判断,模板附件做区域遮罩。
FBO:自定义帧缓冲
FBO(Framebuffer Object) 是自己创建的帧缓冲——渲染结果不直接到屏幕,而是写入一张或多张纹理。之后这些纹理可以被后续着色器读取再做处理。
这就是后处理(Post-Processing) 的基础:先把场景渲染到 FBO 的纹理上,再用一个全屏四边形 + 后处理着色器对这张纹理做模糊 调色 辉光 抗锯齿等效果,最终输出到默认帧缓冲显示。
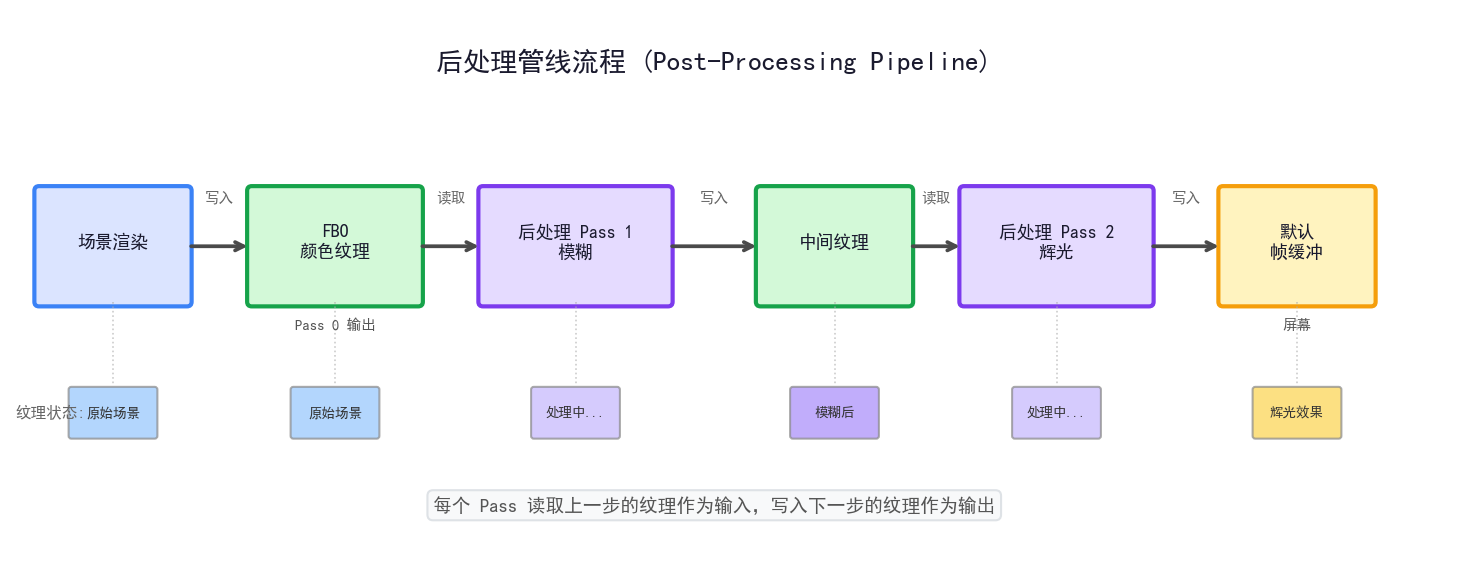
这张图展示了 Mipmap 各级别的实际效果——每级尺寸减半 细节越来越模糊,GPU 根据物体在屏幕上的大小自动选择合适的级别。
MC 里 RenderTarget 就是 FBO 的抽象封装:
// com.mojang.blaze3d.pipeline.RenderTarget
public abstract class RenderTarget {
public int width;
public int height;
public final boolean useDepth;
protected @Nullable GpuTexture colorTexture; // 颜色附件(纹理)
protected @Nullable GpuTextureView colorTextureView;
protected @Nullable GpuTexture depthTexture; // 深度附件(纹理)
protected @Nullable GpuTextureView depthTextureView;
}
colorTexture 和 depthTexture 就是 FBO 的两个附件——都是 GpuTexture 对象,既可以被当前 pass 渲染写入,也可以被下一个 pass 当纹理读取。
渲染到纹理(Render To Texture)
FBO 最直接的用途就是"渲染到纹理":
绑定自定义 FBO 为当前渲染目标
正常渲染场景(写入 FBO 的纹理附件)
解绑 FBO,切回默认帧缓冲
把 FBO 的颜色纹理作为
sampler2D传给后处理着色器画一个覆盖全屏的四边形,着色器对纹理做变换
MC 的后处理管线(模糊 辉光 实体发光描边等)全部基于这个模式。MC 里 TextureTarget 是可调大小的 FBO 实现,MainTarget 是主帧缓冲的 wrapper。
MRT:多渲染目标
MRT(Multiple Render Targets) 是 FBO 的进阶用法——一个 FBO 挂多个颜色附件,片段着色器一次性输出多份数据:
// MRT 片段着色器
out vec4 fragColor0; // 颜色附件 0:最终颜色
out vec4 fragColor1; // 颜色附件 1:法线
out vec4 fragColor2; // 颜色附件 2:深度/材质 ID
一次渲染同时产出颜色 法线 深度等多张纹理——这就是延迟渲染(Deferred Rendering) 的 G-Buffer 阶段。MC 原版不用延迟渲染,但很多光影包(如 SEUS Iris)用 MRT 实现高级光照。
双缓冲与 VSync
屏幕刷新是逐行扫描的。如果渲染到一半就把帧缓冲内容送到显示器,画面上半部分是新帧下半部分是旧帧——这就是撕裂(Tearing)。
双缓冲解决这个问题:维护前缓冲(正在显示)和后缓冲(正在渲染)两块内存。渲染完毕后一次性交换——叫 SwapBuffers。
VSync(垂直同步) 进一步保证 SwapBuffers 只在显示器完成一次刷新时发生。代价是如果渲染来不及,帧率会从 60 掉到 30(必须等下一次刷新)。
1.8 混合与测试
1.2 节管线概览里简单提过测试和混合。这一节展开讲——这两个机制决定了"哪些片段最终能变成像素"以及"重叠的半透明物体如何叠加"。
深度测试(Depth Test)
问题:遮挡关系
3D 场景里物体有前有后。如果不做任何处理,后绘制的物体会覆盖先绘制的——绘制顺序决定了画面,这显然不对。
解决:深度缓冲(Z-Buffer)
GPU 维护一个和屏幕同大小的深度缓冲,存储每个像素位置目前最近物体的深度值(0.0 = 最近,1.0 = 最远)。
渲染片段 A (深度 0.3):
深度缓冲当前值 = 1.0 (初始值)
0.3 < 1.0 → 测试通过,写入颜色,更新深度缓冲为 0.3
渲染片段 B (深度 0.5,同一像素位置):
深度缓冲当前值 = 0.3
0.5 > 0.3 → 测试失败,丢弃片段 B(被 A 遮挡)
渲染片段 C (深度 0.1,同一像素位置):
深度缓冲当前值 = 0.3
0.1 < 0.3 → 测试通过,覆盖 A,更新深度为 0.1
不管绘制顺序如何,最终都是最近的物体显示。这就是深度测试的价值——绘制顺序无关。
深度比较函数
MC 里通过 DepthStencilState 配置深度测试:
// com.mojang.blaze3d.pipeline.DepthStencilState
public record DepthStencilState(
CompareOp depthTest, // 比较函数
boolean writeDepth, // 是否写入深度缓冲
float depthBiasScaleFactor, // 深度偏移(解决 Z-fighting)
float depthBiasConstant
) {
public static final DepthStencilState DEFAULT =
new DepthStencilState(CompareOp.LESS_THAN_OR_EQUAL, true);
}
常用比较函数:
Z-Fighting 问题
两个面深度值几乎一样时,浮点精度不足导致闪烁——交替通过/不通过深度测试。MC 里墙壁上的画框就容易出这个问题。
解决方法是深度偏移(Depth Bias):给其中一个面的深度加一个微小的偏移量。MC 的 DepthStencilState 里的 depthBiasScaleFactor 和 depthBiasConstant 就是干这个的。
深度缓冲精度
深度缓冲通常是 24 位或 32 位浮点。但精度不是均匀分布的——近处精度高,远处精度低(因为透视投影的非线性映射)。
这意味着:近裁剪面设太小(比如 0.001)会严重浪费远处的精度,导致远处物体 Z-fighting。MC 的近裁剪面设置在 0.05 左右,是精度和近处截断的平衡。
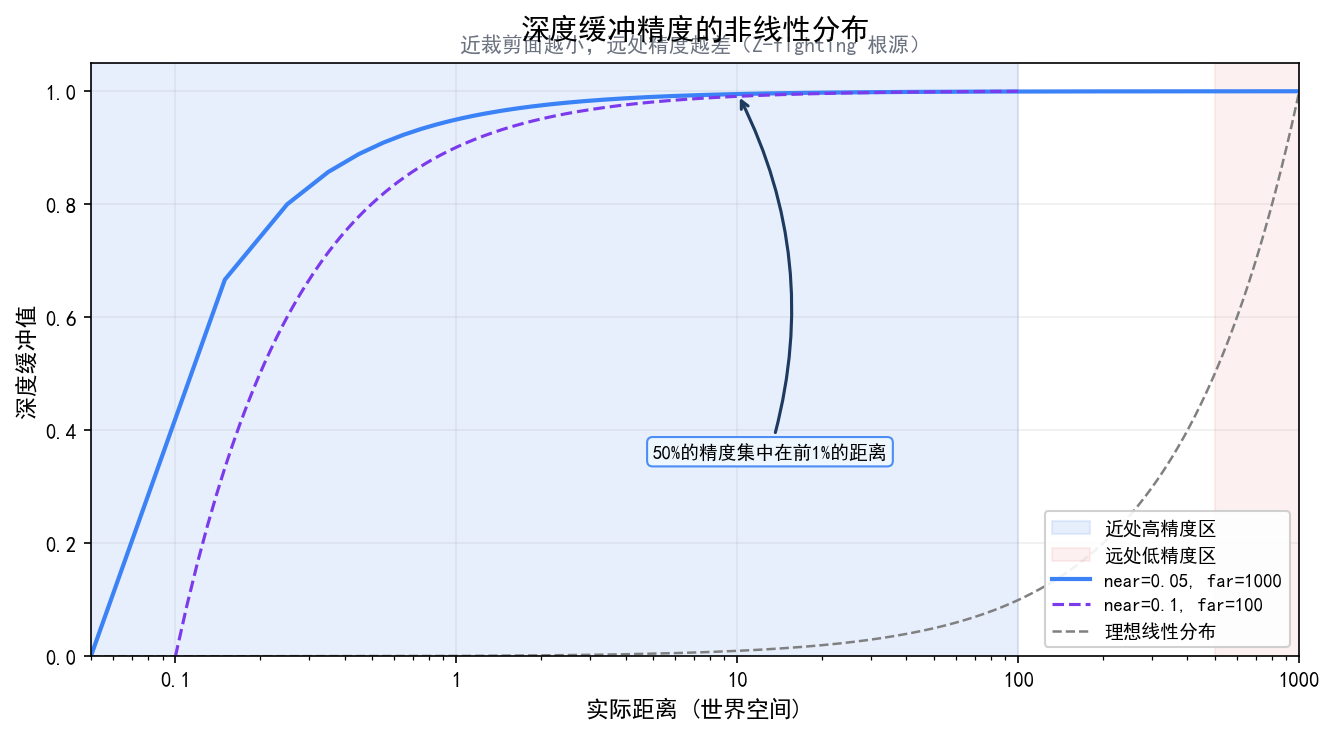
这张图展示了深度缓冲值和实际距离之间的非线性关系——绝大部分精度集中在近处,远处物体共用极少的精度区间。
模板测试(Stencil Test)
模板缓冲是一个 8 位整数缓冲——每个像素位置有一个 0-255 的模板值。
原理:先渲染某些物体时"标记"模板缓冲(比如把某个区域的模板值设为 1),后续渲染时根据模板值决定是否允许通过。
MC 里模板测试的典型用途是实体发光描边:先渲染实体标记模板区域,再渲染一个稍大的轮廓只在模板区域外的像素通过。
混合(Blending)
问题:半透明物体
深度测试是"非 A 即 B"——要么新片段通过覆盖旧的,要么丢弃。但半透明玻璃需要的是"看到玻璃的同时也能看到后面的方块"。这就是混合要解决的问题。
混合公式
混合公式的一般形式:
最终颜色 = 源颜色 × 源因子 + 目标颜色 × 目标因子
源颜色(Source):正在渲染的新片段颜色
目标颜色(Destination):帧缓冲中已有的颜色
因子(Factor):权重系数
MC 里 BlendFunction 预定义了各种混合模式:
// com.mojang.blaze3d.pipeline.BlendFunction
// 标准半透明:src × alpha + dst × (1 - alpha)
public static final BlendFunction TRANSLUCENT = new BlendFunction(
SourceFactor.SRC_ALPHA,
DestFactor.ONE_MINUS_SRC_ALPHA,
SourceFactor.ONE,
DestFactor.ONE_MINUS_SRC_ALPHA
);
// 加法混合:src × 1 + dst × 1(发光 粒子 闪电效果)
public static final BlendFunction ADDITIVE = new BlendFunction(
SourceFactor.ONE, DestFactor.ONE
);
// 闪光效果:src × srcColor + dst × 1
public static final BlendFunction GLINT = new BlendFunction(
SourceFactor.SRC_COLOR, DestFactor.ONE,
SourceFactor.ZERO, DestFactor.ONE
);
常见混合模式对比

这张图展示了四种混合模式的实际视觉效果——同一个前景图层叠加到同一个背景上,不同公式产生完全不同的画面。
半透明排序问题
混合有一个致命限制:绘制顺序相关。
如果 A(alpha=0.5)在 B 前面,正确结果是先画 B 再画 A(远到近)。如果顺序反了,A 先写入帧缓冲,B 再混合时看到的"目标颜色"是 A 而不是背景——结果完全不对。
因此半透明物体必须从远到近排序后绘制。MC 对半透明方块(玻璃 水)做了排序处理,但排序有性能开销,且面级别排序不完美——这就是 MC 水面偶尔闪烁的根源。
不透明物体则无所谓顺序——深度测试保证正确性。所以渲染顺序的最佳实践是:先画所有不透明物体(任意顺序,深度测试搞定遮挡),再画所有半透明物体(远到近排序)。
写入遮罩(Write Mask)
有时你想做深度测试但不想写入颜色(比如 shadow map 只关心深度),或者想写颜色但不更新深度缓冲。MC 通过 ColorTargetState.writeMask 位掩码控制:
// com.mojang.blaze3d.pipeline.ColorTargetState
public static final int WRITE_RED = 1; // 0001
public static final int WRITE_GREEN = 2; // 0010
public static final int WRITE_BLUE = 4; // 0100
public static final int WRITE_ALPHA = 8; // 1000
public static final int WRITE_ALL = 15; // 1111
public static final int WRITE_NONE = 0; // 0000
WRITE_NONE 配合深度写入开启 = 只写深度不写颜色——用于 depth pre-pass(先跑一遍只写深度,第二遍实际着色时跳过被遮挡的片段,省着色计算量)。
1.9 OpenGL 状态机
最后一个概念——也是很多人写渲染代码时最容易踩坑的地方。
OpenGL 是一个巨大的状态机
OpenGL 的设计哲学和函数式编程完全相反——它是一个全局可变状态机。所有渲染配置(当前绑定的纹理 激活的着色器 启用的深度测试 混合模式等)都是全局状态。调用 glDrawArrays() 时,GPU 用的是"此刻所有全局状态的快照"。
做后端类比:想象一个 HTTP 框架,所有 handler 共享一个全局 Context 对象,你设置了什么 header 编码 超时时间都是全局生效的——下一个 handler 看到的是你修改后的状态。如果忘记恢复,就会"污染"后续请求。OpenGL 状态机就是这种模式。
状态类别
OpenGL 的全局状态大致分以下几类:
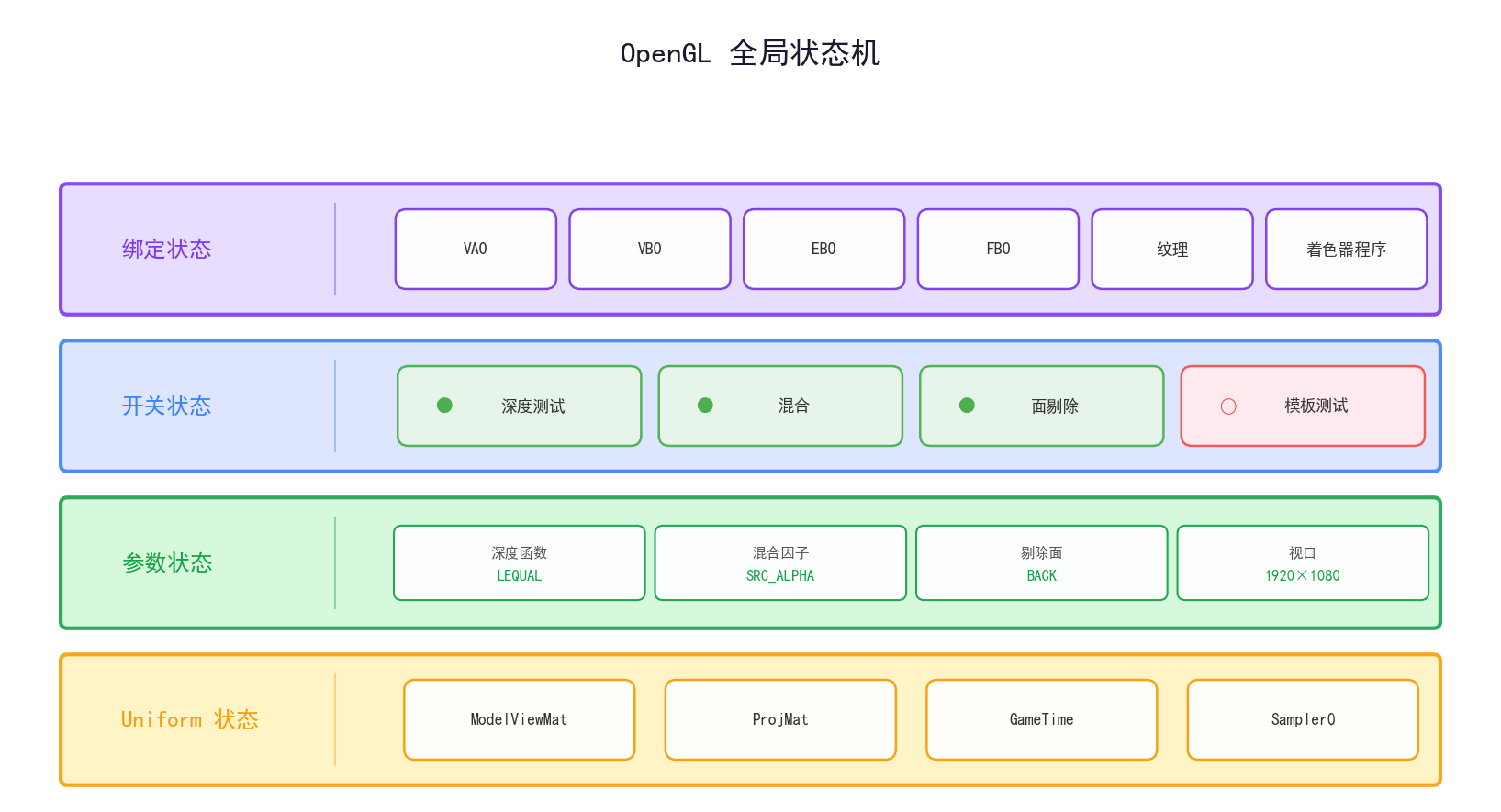
这张图展示了 OpenGL 状态机的四个层级——绑定状态 开关状态 参数状态 Uniform 状态,任何一个被修改后如果没有恢复都会影响后续渲染。
状态泄漏问题
状态机最大的坑是状态泄漏——函数 A 修改了状态但没恢复,函数 B 在不知情的情况下继承了被修改的状态,导致渲染异常。
// 错误示例:状态泄漏
void renderGlass() {
glEnable(GL_BLEND); // 开启混合
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);
// 画玻璃...
// 忘记关闭混合!
}
void renderBlock() {
// 此时混合仍然开启——不透明方块被错误地做了混合
// 画方块...
}
MC 的解决方案:RenderPipeline
MC 最新版本引入了 RenderPipeline 对象,把渲染一个物体所需的全部状态封装到一个不可变对象里:
// com.mojang.blaze3d.pipeline.RenderPipeline(简化)
public class RenderPipeline {
private final Identifier vertexShader; // 着色器
private final Identifier fragmentShader;
private final VertexFormat vertexFormat; // 顶点格式
private final VertexFormat.Mode vertexFormatMode;
private final @Nullable DepthStencilState depthStencilState; // 深度/模板配置
private final boolean cull; // 是否背面剔除
private final ColorTargetState colorTargetState; // 混合 + 写入遮罩
private final PolygonMode polygonMode; // 填充/线框
}
每次 draw call 前,引擎把 RenderPipeline 里的状态一次性应用到 GPU——不再依赖手动设置和恢复。这是 Vulkan / Metal 等现代图形 API 的设计理念:状态对象化,不可变,一次性绑定。
背面剔除(Face Culling)
三角形有正面和背面(由顶点绕序决定——逆时针为正面)。对于封闭模型(方块),背面永远看不见,渲染它纯粹浪费算力。
开启背面剔除后,GPU 跳过所有背面三角形——减少大约一半的片段着色器开销。MC 的方块 实体都开启了背面剔除。但半透明面(玻璃)和双面面片(植物)需要关闭剔除。
RenderPipeline 里的 cull 字段控制这个开关。
视口(Viewport)
视口定义了"渲染结果映射到窗口的哪个区域"。通常是整个窗口,但分屏渲染(如多人模式)会设置为窗口的一部分。
glViewport(x, y, width, height);
MC 在窗口 resize 时通过 RenderTarget.resize() 同步更新帧缓冲和视口大小。
状态查询与调试
OpenGL 允许查询当前状态(glGet* 系列函数),但调用开销大,不适合生产环境。MC 通过 RenderSystem.assertOnRenderThread() 确保所有渲染操作都在正确的线程上——这是另一个状态机的"陷阱":OpenGL context 绑定到线程,跨线程调用 GL 函数是未定义行为。
MC 的做法是:所有 GL 调用都在渲染线程上执行,游戏逻辑线程通过提交 Runnable 到渲染线程队列来间接触发渲染操作。
从 GPU 的并行架构到渲染管线的流水线,从顶点数据的内存布局到着色器编程,从矩阵变换的坐标空间到纹理系统的图集设计,从帧缓冲的后处理管线到混合测试的遮挡与透明,再到状态机的全局管理——这九个模块构成了理解 Minecraft 渲染系统的完整基础。
要知其然也要知其所以然。

参与讨论
(Participate in the discussion)
参与讨论