

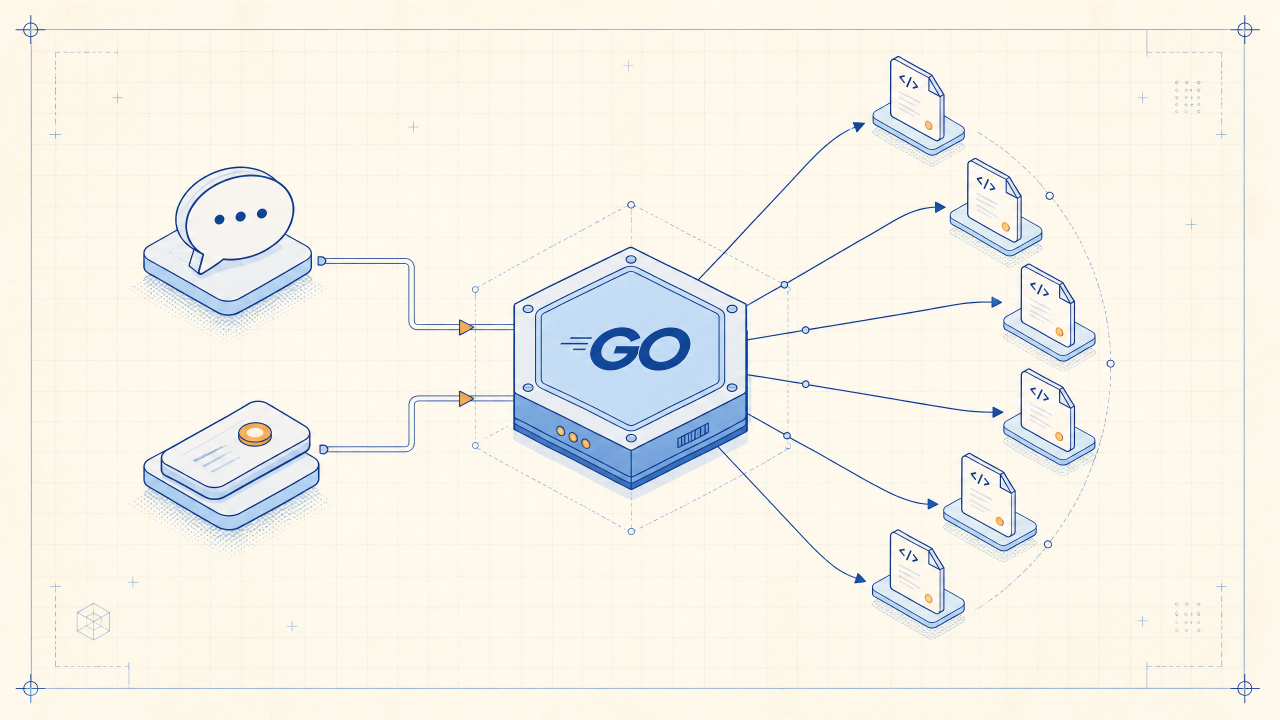
上一篇说到把 Node 插件框架换成了 Lua 基座之后,所有命令分发都收敛到 on_message.lua 一个文件里。开始几条命令时一切都好,写到第十条就开始难受——一长串 if cmd == "..." elseif cmd == "...",参数解析散在各处,产品别名 resolve 在多个脚本里复制粘贴。
这篇文章讲我怎么把命令分发挪回 Go 侧,但又不让 Lua 失去热更新的灵活性。核心思路一句话:Go 负责匹配和分参,每个命令一个 Lua 文件,文件自己声明元数据。
现象:分发逻辑越长越脏
on_message.lua 一开始只有几个分支:构建、版本、帮助。每个分支三五行,写一个 if 就完事。
后来加了快照、测试版、临时版、正式版、发版、版本详情、状态、刷新配置、查询。12 个命令塞在同一个文件里,超过 100 行,且每条命令的参数解析方式都不一样。
elseif cmd == "正式版" or cmd == "stable" then
local bump = parts[2] or ""
if bump ~= "patch" and bump ~= "minor" and bump ~= "major" then
feishu.reply_text(message_id, mention .. "请指定版本类型: patch / minor / major")
else
local product = resolve_product(parts[3])
local builder = dofile(SCRIPT_DIR .. "/lib/builder.lua")
builder.run_build(product, bump, chat_id, message_id, operator_id)
end
更糟的是 on_card_action.lua 里又复制了一份 resolve_product,两份独立维护。
原因:Lua 不擅长当路由层
把命令分发放在脚本里有三个坏处:
重复的解析骨架。每个分支都在做一样的事——parts[1] 取命令、parts[2..n] 取参数、判空、转产品名、检查权限。这些是路由层该干的活,不是业务逻辑。
没有声明性。你看 on_message.lua 100 行的脚本,看不出来这个机器人到底支持哪些命令、各自需要什么参数、谁有权限调。命令清单和实现混在一起。
新增命令的成本不低。要加一条「查询」命令,得在 on_message.lua 加 elseif 分支、在 cards.lua 帮助卡片里加说明、可能还要在 on_card_action.lua 配合一份。一处遗漏就出现「能用但不显示」或「显示但不响应」。
方案:Go 路由 + Lua 自注册元数据
新方案这样组织:
scripts/
├── commands/ # 每条命令一个文件
│ ├── build.lua
│ ├── query.lua
│ ├── stable.lua
│ └── ...
├── lib/ # 业务库(不变)
└── on_message.lua # 降级为 fallback
每个命令脚本返回一个 table,里面声明自己的元数据 + handle 函数:
-- scripts/commands/build.lua
return {
meta = {
name = "build",
aliases = {"构建", "快照", "canary"},
args = {
{ name = "product", required = false, resolve = "product" },
},
permission = "all",
},
handle = function(ctx)
local builder = dofile(SCRIPT_DIR .. "/lib/builder.lua")
builder.run_build(ctx.args.product, "canary",
ctx.chat_id, ctx.message_id, ctx.operator_id)
end,
}
Go 收到消息时做四件事:扫目录 -> 读 meta -> 匹配 -> 执行 handle。匹配上就执行,匹配不上就 fallback 到旧的 on_message.lua,平稳过渡。

关键决策:每次匹配都重新读 meta
最早想过启动时扫一遍目录、缓存到内存的命令表里。但这就丢掉了 Lua 基座最大的优势——改完即生效。
最终选的是「每次事件触发时重新扫描」。看起来像浪费,实际上:
命令脚本通常 20-30 行,gopher-lua 加载 + 执行只取 meta,开销在百微秒级。
命令数量量级是 10-20,遍历一遍不过两三毫秒。
飞书消息事件 QPS 极低,这个开销完全感知不到。
代价换来的是:写 Lua 脚本的人不需要重启服务、不需要重新编译、不需要触发任何 reload,存盘下一条消息就生效。这一点对于「机器人需求来一条加一个命令」的迭代节奏太重要。
为了让 meta 读取更轻,路由器扫 meta 时用的是裁剪过的 Lua VM,只开 base / table / string 三个标准库,不注册业务模块。命令真正命中之后才创建完整 VM 执行 handle。
// 读 meta:轻量 VM,只解析 return 出来的 table
L := lua.NewState(lua.Options{
RegistrySize: 512,
SkipOpenLibs: true,
})
lua.OpenBase(L); lua.OpenTable(L); lua.OpenString(L)
L.DoFile(scriptPath)
参数解析与产品别名 resolve
meta 里 args 数组按位置定义参数。如果某个参数声明 resolve = "product",Go 会自动走配置文件里的 build.products[].aliases 表,把「设计师」「上位机」这类别名换成标准产品名。
args = {
{ name = "product", required = false, resolve = "product" },
}
// router.go 里
if def.Resolve == "product" && rawVal != "" {
rawVal = r.resolveProduct(rawVal)
}
别名 resolve 这件事从此只在 Go 里写一份。on_message 和 on_card_action 里的两份重复实现可以删掉。
卡片回调走同一套路由
飞书卡片的按钮回调和文本命令是两条不同的事件路径,但本质上都是「一个动作触发一段处理」。原来 on_card_action.lua 自己有一套独立的分发,现在让它复用命令路由——meta 里加一个 card_actions 字段:
return {
meta = {
name = "query",
aliases = {"查询", "开启进度查询"},
card_actions = {"query_progress"}, -- 卡片按钮的 action 名
},
handle = function(ctx)
local form_value = EVENT.form_value or {}
if form_value.issue_input then
-- 表单提交逻辑
else
-- 文本命令逻辑:发送模板卡片
feishu.send_template_card(ctx.chat_id, "AAqN6rZzGjYMu", { version = "1.0.2" })
end
end,
}
Go 收到 card_action 事件时,从 value.action 取动作名,遍历 commands/ 找声明了对应 card_action 的脚本。文本命令和卡片回调共享同一份业务实现,不再有两份独立的查询逻辑。

权限层:admin 与白名单
meta 里加一个 permission 字段,三种取值:
"all":所有人可用,默认值。"admin":仅 config.yaml 里permissions.admins列出的 open_id。"ou_xxx,ou_yyy":逗号分隔的白名单,临时开权限给某几个人时方便。
-- stable.lua
meta = {
name = "stable",
aliases = {"正式版"},
permission = "admin", -- 正式版只允许管理员触发
}
权限在路由器里检查,不通过的 operator_id 拿到一句「无权限执行此命令」就结束,handle 函数根本不会被调用。业务脚本里再也看不到 if operator_id ~= "..." then return end 这类样板代码。
效果:写命令变成填表
加一条新命令现在的成本:
在
scripts/commands/下新建一个.lua文件。写 meta(命令名、别名、参数、权限)。
写 handle 函数(业务逻辑)。
存盘。
不需要改 Go 代码,不需要重启服务,不需要在 on_message.lua 里加 elseif,不需要在帮助文档里同步——后续可以在路由器里加一个 help 内置命令,遍历 commands/ 自动生成帮助卡片,命令清单永远是真实的。
更重要的是 Lua 脚本变得干净了。每个文件只关心一件事,元数据声明在头部一目了然,业务逻辑在 handle 里专心做事。写脚本的姿势从「往 100 行的 if 链里塞一个分支」变成「填一张声明表」。
边界与遗留
这套路由不是银弹。有两个边界要承认:
meta 读取仍然有成本。如果哪天命令数量到几十个、QPS 到每秒几十,每次扫目录的开销会显出来。到那一步可以加文件 mtime 缓存——文件没变就用上次的 meta,变了再重读。当前规模下不写这个缓存,省的是「过早优化」的代价。
分发路径还在用文件名匹配。一个文件对应一个命令,文件名和 meta.name 没强绑定,重命名文件不影响行为,但目录里的「同名文件覆盖」语义也就没了。如果以后引入命令优先级或显式覆盖,要在 meta 里加字段。
实战:进度查询——从 issue 号到提交摘要
命令路由做好之后,第一个跑通的非平凡命令是「进度查询」。用户在飞书群里发一张表单卡片,填 issue 编号,选时间范围,点提交——机器人自动找到关联分支、拉取 Git 提交记录、调 AI 生成进展通报。
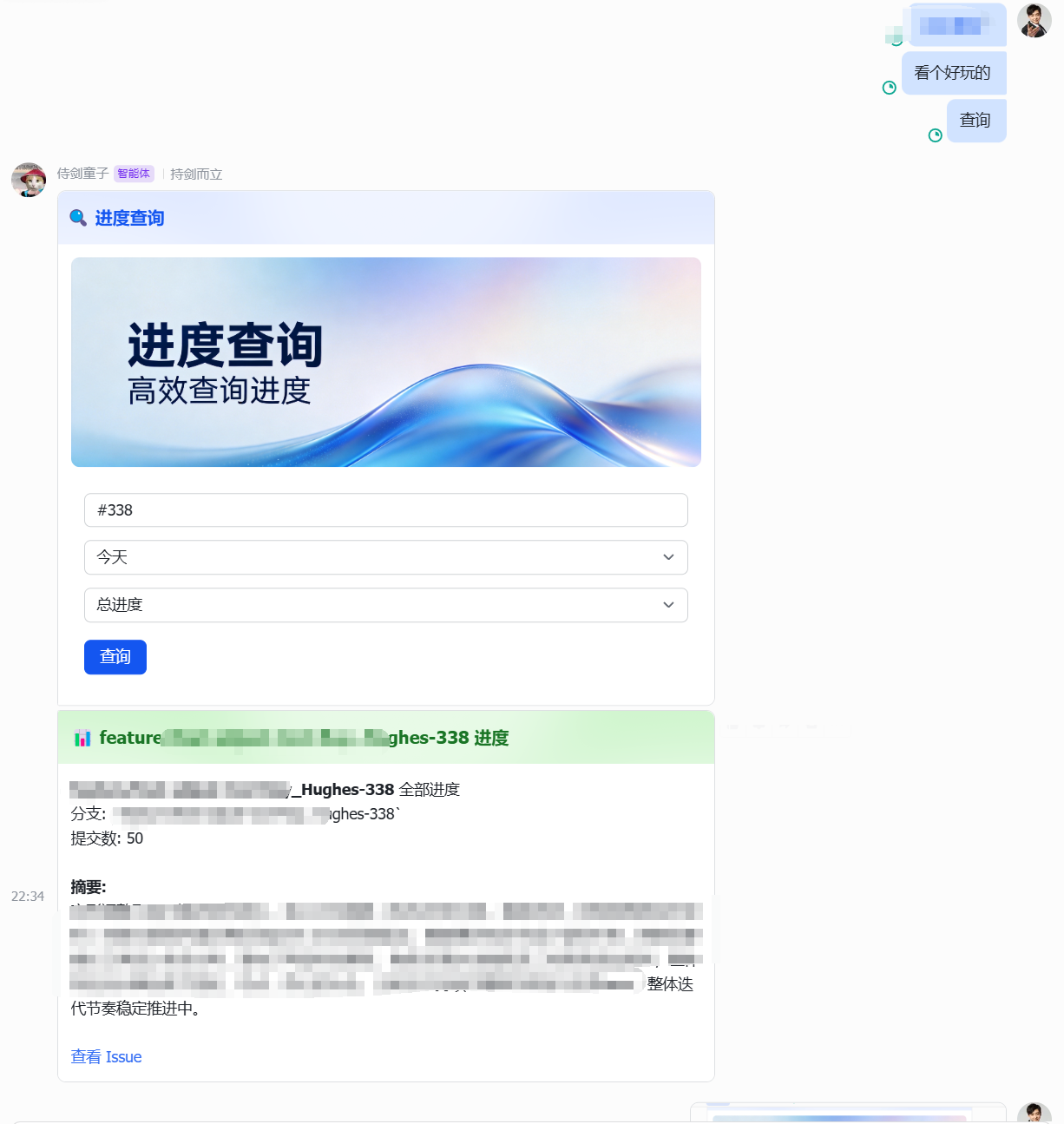
分支发现的三步策略
issue 和分支之间没有固定的命名规范。有人叫 feature/338-xxx,有人叫 feat-adjust-tool-Ray_Hughes-338,issue 号可能在开头、中间、末尾。最初尝试拉全量分支在 Lua 侧做正则匹配,命中率很低。
最终方案走 GitLab API 三步搜索:
-- 1. 查关联 MR(issue 和 MR 显式关联时直接命中)
gitlab_json("/projects/" .. id .. "/issues/" .. iid .. "/related_merge_requests")
-- 2. 搜索 MR 标题/描述含 issue 号的
gitlab_json("/projects/" .. id .. "/merge_requests?state=all&search=" .. iid)
-- 3. 搜索分支名含 issue 号的
gitlab_json("/projects/" .. id .. "/repository/branches?search=" .. iid)
三步按优先级走,任何一步命中就停。第一步最准但依赖手动关联,第二步覆盖「MR 描述里写了 closes #338」的情况,第三步兜底通过分支名模糊匹配。实测这个组合在我们的仓库里 100% 能找到正确分支。
Lua 解析 JSON 的坑:为什么要做 json 模块
一开始 Lua 侧没有 JSON 解析库。GitLab API 返回的 JSON 字符串靠正则提取字段:
-- 这种写法对嵌套对象直接翻车
local id = body:match('"id"%s*:%s*(%d+)')
GitLab 返回的 issue 对象里 id 不止一个——id、author.id、namespace_id。正则匹配第一个 "id": 可能拿到完全不相关的字段。%b{} 匹配花括号对在嵌套 JSON 里也会把子对象当成独立 item 解析。
最终在 Go 侧加了一个 json 绑定模块,内部用 encoding/json 做正确的递归解析:
local json = require("json")
local data = json.parse(resp.body)
-- data 是完整的 Lua table,嵌套结构正确
local project_id = data.id
local author_name = data.author.name
两行替代了之前二十多行的 pattern matching,而且不会再因为字段顺序变化或嵌套层级变化而出错。
AI 摘要的措辞陷阱
进度查询的最后一步是把 commit 列表交给 AI 生成摘要。第一版 prompt 写的是「总结这些提交完成了什么工作」,AI 直接输出「已完成 XXX 功能的开发,实现了 YYY」——但 issue 还没关。产品经理看到会以为做完了。
修复方式是把 issue 的 state 传给 prompt,让 AI 根据状态选择措辞:
local tone
if issue_state == "closed" then
tone = "这个需求已经收尾,可以使用『已交付』『已落地』等表述。"
else
tone = "这个需求还在迭代中,不要使用『完成』等绝对化表达," ..
"用『已推进至』『正在打磨』『当前进展』等更贴近研发节奏的说法。"
end
AI 不知道你的 issue 是不是真的做完了。不给边界条件,它会默认往「结论感」走,因为那样读起来更流畅。prompt 必须显式约束。
飞书模板卡片的几个坑
进度查询的表单入口用的是飞书模板卡片(send_template_card)。从 API 调通到真正在群里看到卡片,中间踩了三个不显眼的坑。
坑一:Webhook 格式和 SDK 格式不是一回事
网上大部分飞书卡片的教程是群机器人 Webhook 方式,请求体是这样的:
{ "msg_type": "interactive", "card": { "type": "template", "data": {...} } }
但 SDK 的 im/v1/messages 接口用的是 content 字段(JSON 字符串),不是 card 字段(对象)。把 Webhook 格式直接复制过来,API 返回 200 但群里什么都不显示——不报错、不提示、静默失败。
正确的 SDK 写法是 content 传序列化后的 JSON 字符串:
content := map[string]any{
"type": "template",
"data": map[string]any{
"template_id": templateID,
"template_version_name": "1.0.2",
"template_variable": variables,
},
}
contentBytes, _ := json.Marshal(content)
// contentBytes 作为 string 传给 Content() 方法
坑二:必须传 template_version_name
模板卡片的 data 里如果不传 template_version_name,API 同样静默成功但不渲染。没有任何文档明确说这个字段是必填的——只在一个 SDK 示例代码的注释里提到「可选,卡片版本号」。
实测结论:如果你的卡片模板有多个版本,必须显式指定版本号。不指定时 API 不报错,但前端不渲染。
坑三:表单组件的 name 属性不能为空
模板卡片通过飞书搭建工具设计,里面有输入框、下拉框这类表单组件。如果任何一个 interactive 组件的 name 属性为空字符串,Create 接口返回:
code=230099 msg=Failed to create card content
ErrCode: 201002; ErrMsg: The name attribute of the interactive component within the form must not be empty.
这个错误信息倒是清楚,但问题在于:搭建工具里组件默认没有 name,你不点进去手动填就是空的。而且你在预览界面看到的卡片一切正常,只有通过 API 发送时才报错。
坑四:模板权限
调通了格式和版本号之后,API 返回 success=true code=0,群里依然看不到卡片。最后发现:模板卡片需要在搭建工具里显式给你的应用(app_id)授权使用权限。
路径:卡片搭建工具 -> 模板设置 -> 使用权限 -> 添加应用。
四个坑的共同特点:API 不报错或者报错信息与真因无关。如果你在接飞书模板卡片时遇到「代码没报错但看不到卡片」,按这四步逐一排查。
收束
把分发挪回 Go 不是退步,是让每一层做自己擅长的事——Go 适合做强类型的路由匹配、参数校验、权限检查;Lua 适合写灵活的业务逻辑、串调能力模块。两者通过一个简单约定(return meta + handle)连起来,互不越界。
进度查询这个例子把整条链路串了起来:命令路由负责分发和参数传递,json 模块负责 API 响应解析,GitLab 三步搜索负责分支发现,AI 摘要负责把 commit 记录变成人能读的话。每一环都是独立的小能力,通过 Lua 脚本串成完整场景。
要知其然也要知其所以然。这次重构的真正收益不是少写了几行 if,而是让"加命令"这件事的认知负担降到了最低——同时用踩过的坑给后来人省几个小时的排查时间。
参与讨论
(Participate in the discussion)
参与讨论