

在 Electron 应用里做计算密集型功能时,最直接的问题通常不是“算法能不能跑”,而是“跑的时候会不会把界面拖住”。
这次优化的对象是一个几何计算阶段。它需要对一批候选参数逐个尝试,并在每次尝试时执行完整的碰撞检测和风险判断。旧实现主要跑在 TypeScript 里,逻辑是串行的:一个候选值算完,再算下一个。单次检测如果需要 1 到 2 秒,几十个候选值叠加后,Electron 渲染进程就会出现明显卡顿,用户看到的就是界面长时间没有响应。
所以这次优化的核心目标不是简单地“把某个函数写快”,而是把计算从 UI 线程里拆出去,让 Electron 的主交互保持稳定,同时让重计算阶段能充分利用 Worker、SharedArrayBuffer 和 WASM。
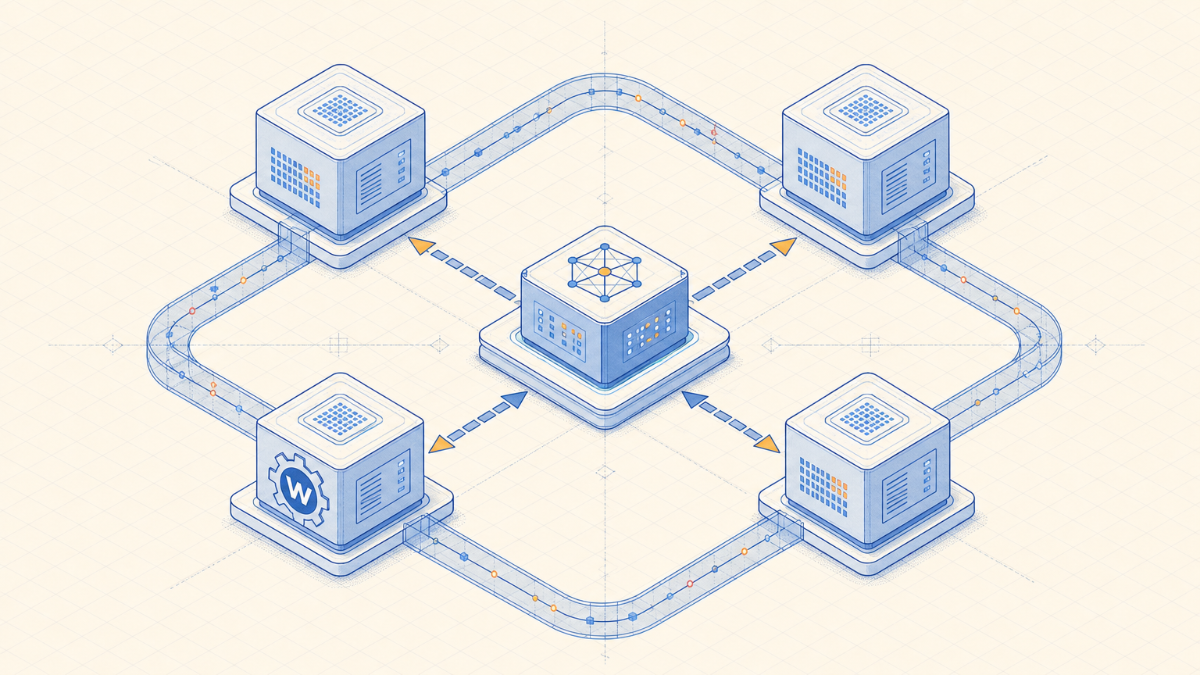
下面这张图先给出整体结构。它不是业务流程图,而是运行时边界图:Renderer 只负责交互,Coordinator Worker 负责调度,Detector Workers 负责并行计算,SharedArrayBuffer 作为跨 Worker 的共享数据区。

为什么要把 Worker 放在核心位置
Electron 应用虽然运行在桌面环境里,但前端部分本质上仍然受浏览器线程模型影响。渲染进程如果承担大量同步计算,界面更新、进度反馈、用户取消操作都会被阻塞。
因此第一步是把求解过程放进 Worker 体系里。
整体结构可以理解为三层:
Renderer 负责发起任务、展示进度和接收结果;
Coordinator Worker 负责调度、序列化数据、管理批次;
Detector Workers 负责真正执行大量候选值检测。
Renderer 不直接参与重计算。它只发送 solve、cancel、dispose 这类消息,并通过进度通道感知当前阶段。这样即使底层计算持续几秒,Electron 界面也不会被同步计算卡死。
Worker 之间不要频繁传大对象
把计算放进 Worker 之后,马上会遇到第二个问题:数据怎么传。
如果每次检测都通过 postMessage 传递大量几何对象,会产生明显的结构化克隆成本。候选值越多,消息越多,性能损耗也越大。
最后采用的是 SharedArrayBuffer。
主线程初始化一块共享内存,Coordinator Worker 和 Detector Workers 都基于这块内存读写数据。几何数据、任务信息、结果槽、进度状态都放在固定区域里。Worker 之间不再来回复制大对象,而是通过偏移量访问同一块内存。
这一步的关键不是“用了共享内存”,而是把共享内存当成一个稳定协议来设计:
control 区存批次号、取消标记、结果计数;
progress 区存当前阶段和进度;
task 区描述每个 Worker 要处理的任务;
result 区由每个 Worker 独占写入;
scratchpad 给每个 Worker 做临时计算。
这样 Electron 渲染层、Coordinator Worker、Detector Worker 和 WASM 内核之间都有清晰边界。
下面这张图更偏执行视角,展示一次任务从 Renderer 发起,到 Worker 并行执行,再到结果聚合返回的过程。为了避免横向过宽,图里把流程按阶段上下展开。

Worker 调度从抢任务改成静态分配
一开始的 Worker 调度更接近传统任务队列:多个 Detector Worker 通过原子操作抢任务。理论上灵活,实际调试成本很高。
在 SharedArrayBuffer 上维护动态队列时,需要处理任务头尾、批次切换、结果计数、取消唤醒等状态。只要一个原子状态没有处理好,就可能出现 Worker 等待超时、旧批次结果混入新批次、或者结果计数永远不达标。
后来改成了静态分配。
Coordinator Worker 在派发前先把候选范围切好,明确每个 Detector Worker 负责哪一段,写到哪个结果槽。Detector Worker 不再抢任务,只处理自己分到的那一块。所有 Worker 完成后,Coordinator 再统一聚合结果。
这个方案少了一些通用性,但更适合固定批量计算:
没有任务竞争;
每个 Worker 写自己的结果区;
批次边界清楚;
超时和取消更容易处理;
问题更容易复现。
对于 Electron 里的重计算任务,可预测性往往比“调度模型看起来更通用”更重要。
WASM 负责热路径,Worker 负责并行边界
Worker 解决的是线程隔离和并行调度,WASM 解决的是热路径计算效率。
这次没有把完整业务逻辑都搬进 WASM,而是只把最重的检测内核放进去。TypeScript 仍然负责调度、数据准备、结果聚合和回退路径。WASM 只接收基础类型参数,比如字节偏移、候选角度、结果区位置,然后直接从 SharedArrayBuffer 对应的线性内存里读取数据。
这样设计有几个好处:
WASM ABI 足够小;
TypeScript 和 WASM 之间不传复杂对象;
热路径里避免 GC;
SIMD 和共享内存更容易启用;
出问题时可以回退到 TypeScript 参考实现。
在 Electron 场景里,这种边界比较实用。业务层仍然保持在 TypeScript 里,WASM 只承担稳定、密集、可测试的计算内核。
算法优化仍然是最大收益来源
Worker 和 WASM 不是银弹。真正最大的收益,来自先把算法里的无效扫描降下来。
旧检测逻辑接近 O(N × M):每个运动片段都可能和所有候选几何做判断。即使用 Worker 并行,也只是把很多无效计算分摊到多个线程上。
后来加了一层规则网格索引。候选几何按 AABB 覆盖范围写入网格 cell,检测时只访问当前片段覆盖到的相邻 cell。这样大部分不可能相交的候选对象根本不会进入判断流程。
这里也踩过一个典型坑:不能只按候选对象中心点放进网格。对象可能跨越多个 cell,只放中心点会导致边界漏检。最终采用的是按 AABB 覆盖区间写入多个 cell,牺牲一点索引大小,换取正确性。
这一步让单次检测从秒级下降到毫秒级。之后 Worker 并行和 WASM 才能进一步放大收益。
这张对比图可以放在这里,帮助读者把“为什么不是只上 WASM”这件事看清楚:性能收益来自多层组合,其中算法降复杂度是最前置的一层。

正确性靠对照测试收敛
这种优化最怕的是结果变快了,但判断结果悄悄变了。
所以整个过程中一直保留 TypeScript 参考路径。WASM 路径和 TypeScript 路径会在固定输入下做对照,不只比较最终结果,也比较中间状态,例如候选数量、阻塞位图、最终选中的参数位置等。
另一个经验是,不要在序列化阶段偷偷做几何修正。序列化层只应该负责把原始数据写进共享内存。任何依赖运行时角度、当前候选值或局部坐标系的计算,都应该留在 WASM 内核里处理。否则 Worker 并行后,很容易出现难以定位的误报或漏报。
最终效果
优化之后,Electron 渲染进程不再直接承担重计算。计算任务通过 Coordinator Worker 调度,再分发给多个 Detector Worker。大块数据通过 SharedArrayBuffer 共享,热路径由 WASM 执行,结果再回到 TypeScript 聚合。
整体变化可以概括为:
原来是 Electron 渲染侧发起串行 TypeScript 计算。
后来变成了 Electron Renderer 负责交互,Coordinator Worker 负责调度,Detector Workers 并行执行,WASM 负责核心检测,SharedArrayBuffer 负责数据共享。
最终效果是,核心检测从秒级降到毫秒级,完整扫描阶段从几十秒降到数秒级。更重要的是,界面线程和计算线程被隔离开,用户可以看到进度,也可以取消任务,Electron 应用的交互稳定性明显提升。
这次优化的结论很朴素:在 Electron 里做重计算,第一步不是急着上 WASM,而是先把计算从渲染线程移走;第二步减少 Worker 间的数据复制;第三步用更合适的数据结构降低计算量;最后再把稳定的热路径交给 WASM。这样得到的性能提升才比较可控,也更容易长期维护。
参与讨论
(Participate in the discussion)
参与讨论